Fix Your Unstable Automated UI Tests
Unstable automated tests are bad. You cannot rely on the results. It takes too much time to investigate if a failure is really a bug or a false positive/negative. By definition UI tests are the worst as there are lots of moving parts involved, and the planets need to be in line for them to pass. Here is a small set of problems that may cause automated browser tests to fail:
- Browser crash/bug
- Selenium server crash/bug
- Network latency
- Page not fully loaded/missing elements on page
- Slow application response
It’s no wonder experienced engineers shy away from UI tests. However you need them. They use the same interface as your end users. They are inevitable if you want to have complete test automation strategy. Bellow you’ll find a few practical tips and tricks how you can improve your existing UI tests and start enjoying your life more.
Background
Recently I had to rework a set of 62 UI tests that use Selenium/Ruby/Page Object to make them more stable. The tests were continuously run on a test environment and they took about 48 minutes to complete.
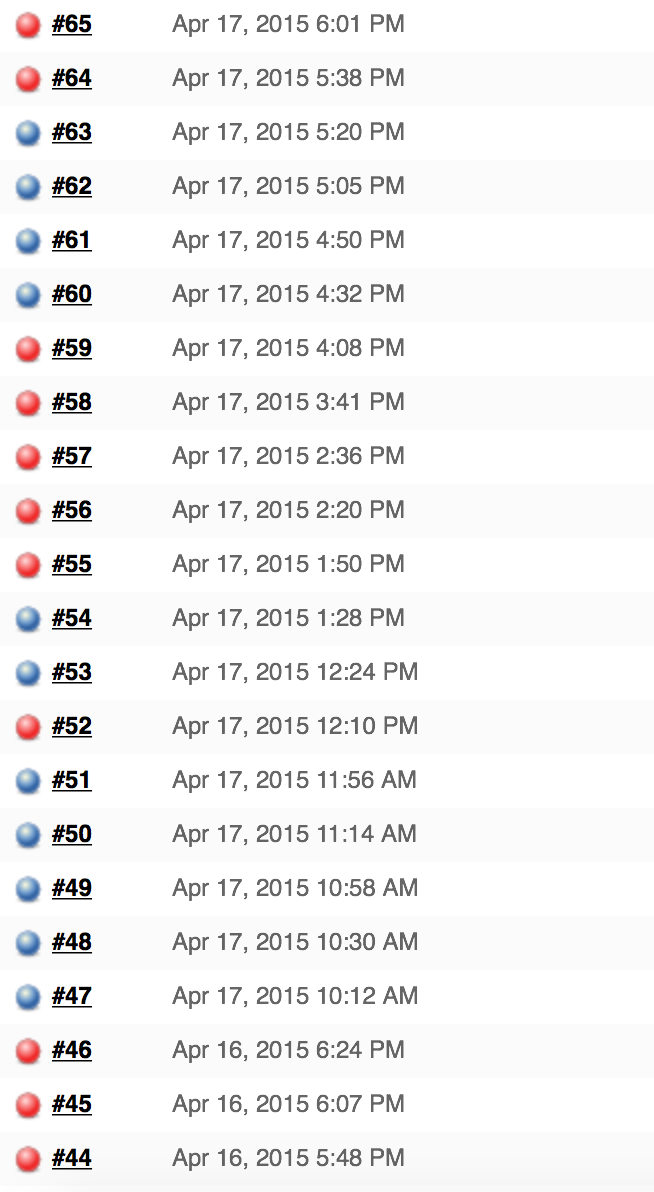
The tests we’re very very flaky. Check the result from running them 22 times in a row. There we’re no code changes to both the tests and to the application in order for the results to be comparable.
As you can see from the screenshot, they passed only 50% of the time. Pretty bad, huh? Do your tests have similar pass/fail rate?
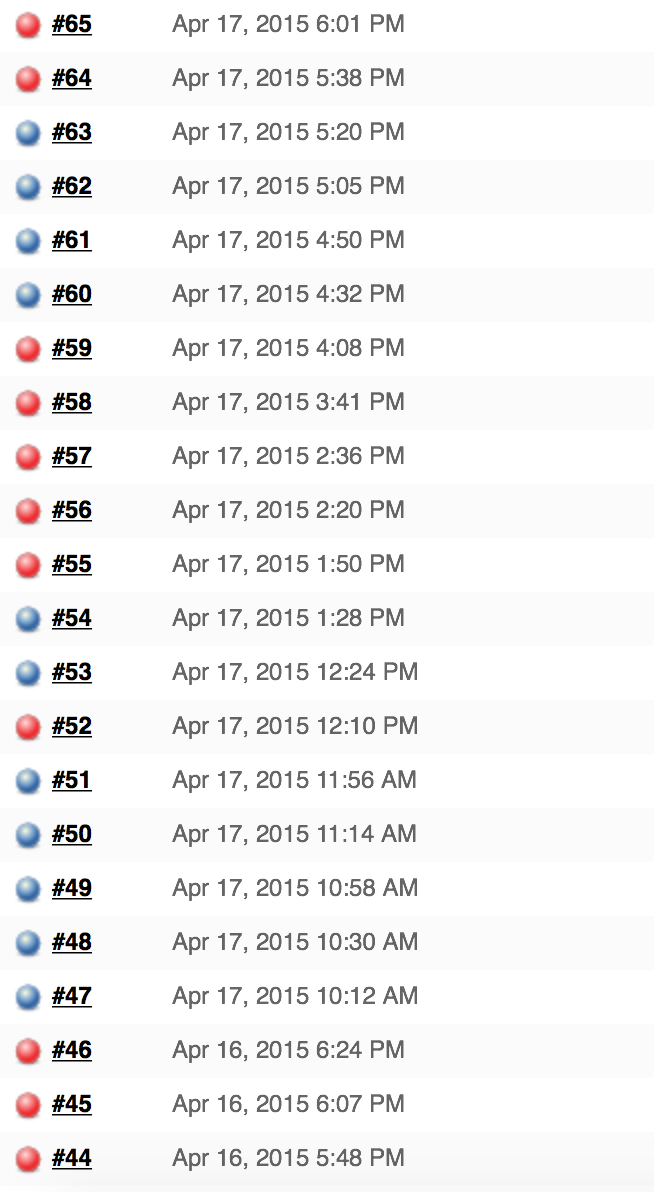
Here is the screenshot after we made all the changes. Again 22 runs consecutively, no code changed. 100% pass rate. Here is how we did that.
Environment Changes
The first and the most important thing is to use separate environment where you run only your automates tests. At the beginning we used to run those tests on common test environment also used by the developers and the QA Engineers (for manual/exploratory testing). It consists of application server and two databases MySQL and Mongo. Some of the databases were also used by developers when they need more data to test with while developing on their workstations.
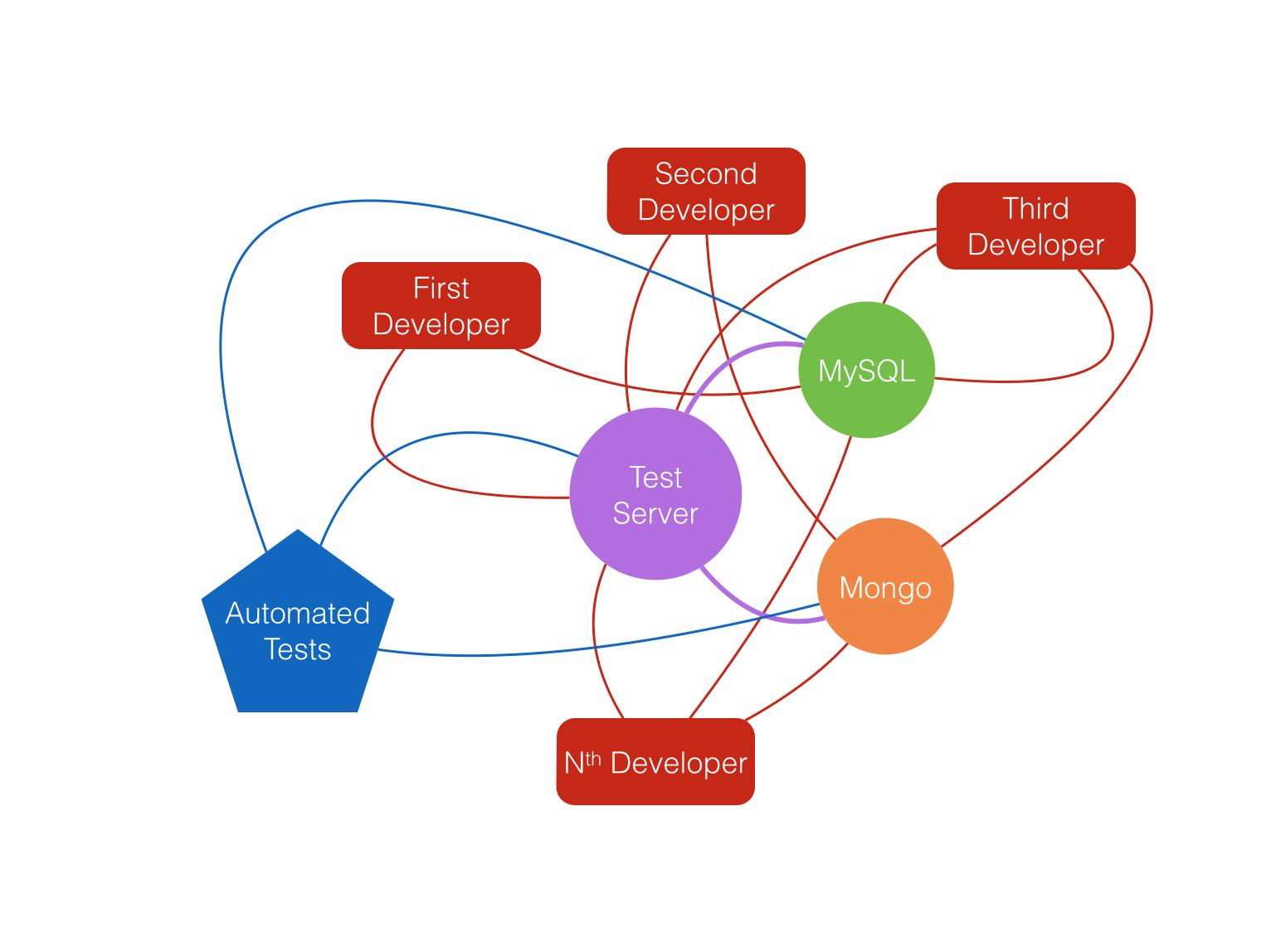
This is not a good setup. This test environment is constantly in flux. Imagine that while the tests are running, someone commits and deploys there new code. Also it’s pretty slow application. Everyone may use the application server or the databases, causing delay to your already slow tests. The solution was to create separate environment, just for the execution of the UI tests. I’m not going into lengthy details of how we did this, as it will be the topic of a long post in the future. Suffice to say, this is how the picture looks like now:
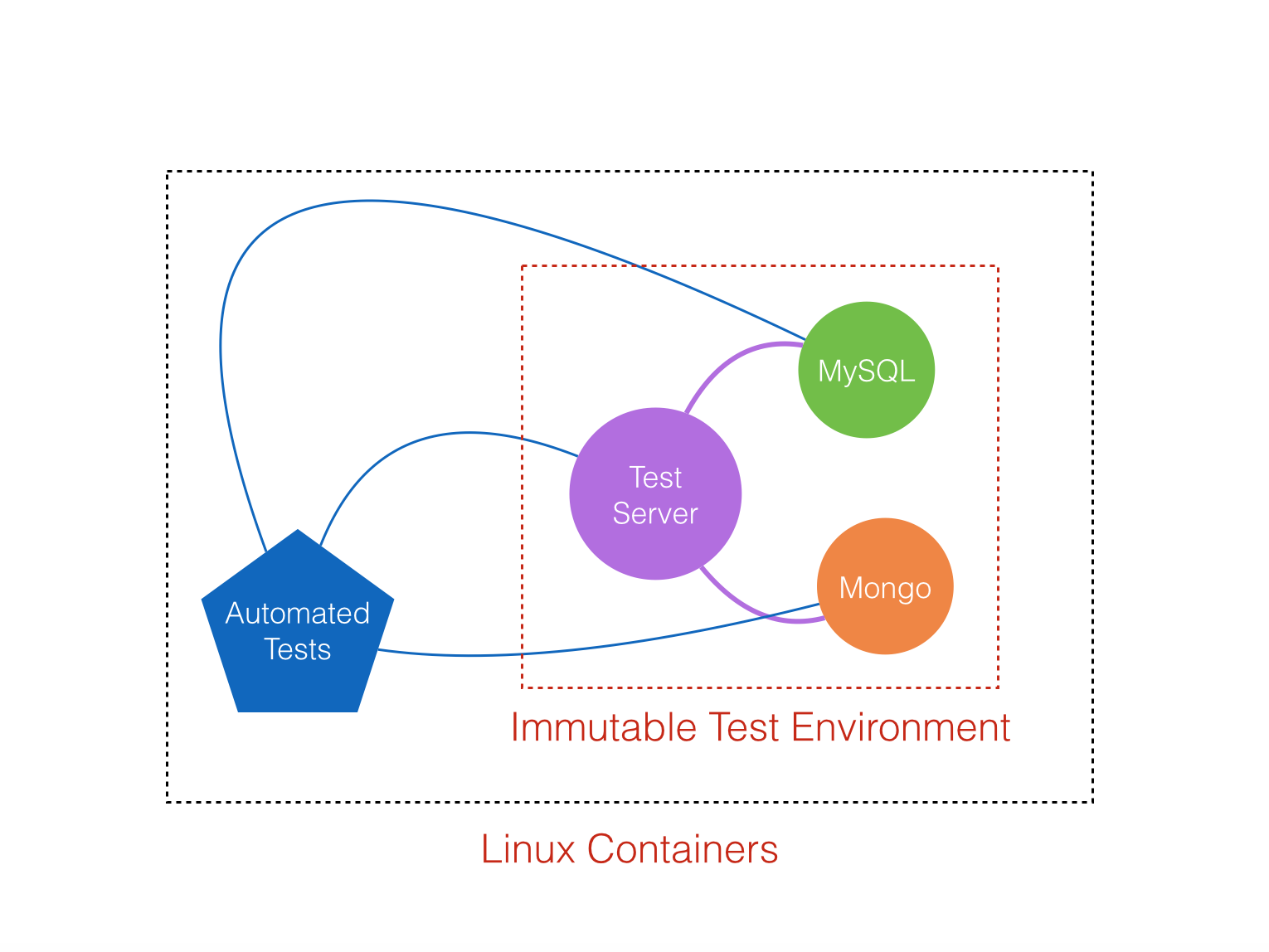
Totally isolated environment, rebuilt from scratch every time you start the UI tests (same thing should apply if you have API tests only). Not only did this improve the stability of the tests, but it also improved their speed. Now they run for about 12 minutes. 4x increase in speed just by switching to dedicated environment - not bad at all.
Our next problem was network latency. We had some packet drops between the CI server, from where the automated UI tests we’re executed and the dedicated UI test environment. Our solution was to run the tests on the same machine that hosted the dedicated UI test environment. This didn’t improve the speed of the tests with much, but improved their stability. For the technically oriented readers - we're using Docker containers. The details of why/how will be in a future post.
Wait Smarter
We had some hardcoded sleeps in some of the tests in the form of:
sleep(20)This is Ruby code, the sleeping time is in seconds. It's a really bad practice, and you should strive to remove all such hardcoded sleeps. The problem is that even if the event that you’re waiting to happen, happens on the 5th second, you will wait for 15 more seconds. You want to be a bit more smarted that than. If you use the Selenium APIs directly you need to use the advances waits.
In our case, the UI automation test framework uses the page object gem that offers similar functionality. There are two types of ‘smart waiting’ that you can implement with the page object - at page and at element level, both are described in details here. We had problems with clicking a button or a link that was not yet present or visible on the page so we changed the code on a bunch of places from:
site.monitor.archive.clickto
site.monitor.archive_element.when_visible(10).clickSometimes you need to wait for an event that’s not related to a DOM element, so you can not use the above methods. For example, we had some API calls that we’re slow to write to the database. In such cases we use Anticipate gem to be a bit smarter.
sleeping(1).seconds.between_tries.failing_after(10).tries do
result = some_operation
raise 'No Data' if result['data'] == []
end
The code will try every second to perform an operation. If the result from this operation is an empty array, an exception will be throw. If we have not reached the maximum retry time - 10 in our case, the exception will be caught silently. If at the 7th try, the array is not empty, no exception will be throw and no more attempts to retry will be made. The test execution continues normally. If on the 10th attempt, the result is still an empty array,exception will be thrown as usual, but this time it will not be caught since the maximum retries would have been reached. Your test will fail at this point.
Obviously you can develop your own function that does the same as this gem, if you’re not using Ruby.
Another kind of waiting that needed to be implemented was to make sure that there are no more pending ajax requests. If your application is using jQuery and your test framework is using the page object gem, you have a nice wrapper and you only need to call:
wait_for_ajax(number_of_seconds_to_retry)What it does in the background is pretty simple. It just executes:
return jQuery.active;If the result returned is zero, then there is no more pending request and you can continue to evaluate the page or continue with the steps of your test. If there are pending requests, you need to wait a bit more until they reach zero before proceeding any further.
If you’re not using jQuery, but some of the new JavaScript MVC frameworks, then there is no universal solution. For example, if your frontend is using Angular, this is how you get the pending Ajax requests count.
Navigation Shortcuts
The logic of most of the existing UI tests was the following:
- Open the login URL
- Enter username and password
- Once logged in the application navigate to some section called a ‘channel’ (by clicking the search option, enter the name of the channel, click find).
- Do stuff on the channel.
- Then evaluate the result.
There are two main problems with this approach - some of the steps are unnecessary longer and thus not failsafe. Steps 1-3 are preconditions to our test. The test should not be concerned how we got to step number 4, where the real execution of what we want to test happens. The faster we get to step number 4, the better.
This first problem is with the login. Why the test needs to go to the login screen, enter username and password and click login. Wouldn’t it be cool (and fast as well as more reliable) to be able to point your browser to a URL and be automatically logged. There are two main approaches how to do this. One of the approaches is to add a cookie via Selenium to your browser. The other approach is to append a token or some other special parameter to the URL so that the server recognizes you and automatically logs you in. Some URL examples:
www.example.com/8971233
www.example.com/access-token/8971233
www.example.com/login?user-token=1234-12345678
In this case we choose the URL parameter over using a cookie. However this mostly depends on your application architecture.
The second problem with the existing test case flow was step number 3 - the navigation to the ‘channel’ we want to run our actual test on. If your test is testing the actual search function, then by all means you need to go through all the details. However in all other cases, you should try to shortcut this step. The one approach to add parameter to the URL to directly navigate you to the portion of the site that you’re interested in:
www.example.com/channel-id/777888
In our specific case we use AngularJS so the solution was to execute the following JavaScript code (using Ruby and Selenium):
browser.execute_script("
rootScope._selector.selected.channels[0]['channel_id'] = '#{social_network_id}';
rootScope.safeApply;")
Fix/Add Checks
Sometimes the login method with direct URL was not working for an obscure reason we still couldn’t figure out. The solution was, after landing on login page, to check for the presence of certain text to verify that the login succeeded. If the text is not there, it means that something has gone wrong. The test retries three times until it finally gives up. This is sufficient to get rid of all problems during the login stage. Here is how the code looks like:
super(browser)
self.class.page_url SITE_LOGIN + user.token
goto
sleeping(1).seconds.between_tries.failing_after(3).tries do
browser.navigate.refresh
wait = Selenium::WebDriver::Wait.new(:timeout => 5)
wait.until do
browser.find_element(:tag_name => "body").text =~ /user logged/
end
endOn couple of places we had way too broad checks that we almost always passing, when they should have failed. For example:
site.body.include? ‘user’
This line will check the all of the body text for the word ‘user’. This is not very precise assertion and we either removed the assertion, or changed it to evaluate more narrow part of the page body.
The Design Error
We found one error that was not technical in nature, but more of a design error. We have different levels of user access to this application - master, agency admin, agency user, advertiser and so on. Master is user access with the highest level of privileges. This access is used only for internal purposes and is never given to the real customers. The master access can see everything that is happening in the application, without any restrictions.
When the automation tests were initially developed they used the Master role. It was supposed to be temporary thing until we figure out all the quirks. However as the saying goes about temporary solutions evolving to permanent ones, no one bothered to use a role other than Master in the subsequent tests.
The problem was that the tests were not realistic and were passing when they should be failing (being able to validate things what should be forbidden because of lower privileges for example), because none of the applications’ customer were actually using this role. Changed it to a default lower privileged role and it was smooth sailing from there.
Speed
Initially we didn’t set to make the tests faster, but more reliable and stable. We achieved 4x speed improvement doing only one thing - using dedicated test environment (which is pretty big undertaking in its own way). But faster tests tested good (pun intended). Currently we want to bring 12 minute test suite execution to less than 3 minutes. On order to do that we need to fix the following:
- Do not contact external services. Some of the application pages are loading content from Facebook, Evergage and Google Analytics. For functional automation test purposes this is not needed.
- Currently node packages are downloaded on every build. Obviously this is too slow and should be removed. Dependencies should be updated on demand.
- Enable parallel run of tests. 4 threads should be enough.
- Try phantomjs. We had problems with it in the past, as it had issues with JS alerts, modal dialogs and other weird stuff. Need to check if it has matured enough.
This will be the topic of future post.
Conclusion
Just because they are UI tests, it does not mean that they should not be reliable. Be meticulous in searching for the root case for flakiness. I hope you'll find some of those tips useful and make your UI automated tests bulletproof. Also remember to obey the automation testing pyramid - write less tests that use the UI. Push tests as low as where the actual decision is being made.