Integration Tests Are Awesome
In April 2017 I gave a talk at CraftConf titled The Ultimate Feedback Loop[1]. In this talk I shared the results of an investigation of almost 200 customer reported bugs in a span of two and a half years. Lots of insights came out but one piece of information stood out in particular. Maybe because it challenged a deeply entrenched belief about the automation testing pyramid. According to this belief, you should have a wide base of unit tests, less API tests[2] and just a small amount of UI tests on top. However our data shows that, for our product, API tests give us the biggest back for the buck. By writing integration tests we can detect 180% more defects that writing unit tests for the same features. How is this possible?
The Testing Pyramid
According to the testing pyramid, the automated tests can be divided into three large groups — unit, API and UI.
Unit tests run only in memory, usually they call a single method, and they don’t interact with the outside world. They don't send data over the network, don’t write to anything to disk and don’t store anything in a database. And because they don’t interact with the outside world, they are so fast and deterministic.
API tests run when the whole application is deployed and operational — e.g. it has a database running, a network and so on. Modern application use the web services layer[3]. The API tests exercise the whole application as is intended to be used by the end customers. It operates one level bellow the UI. API tests interact with the application the way another application would — not the way a human would.
UI tests also need a fully deployed application to operate. However they interact with the application they way a human would do — via HTML (web browser) or in case of a mobile app with the touch interfaces. Under the skin, those interfaces are using API calls to send data to and and read from the backend. Those tests are the most realistic, however they are also the most brittle[4] and require high maintenance because there are so much more moving parts.
Unit Tests Are Not Enough
When we investigated each customer reported defect we could link it back to the location in the codebase where the fix for it was made. It's easy because developers put the bug id in the commit message.
Looking at the methods where the fixes were made, we found out that 7% of them were already covered with unit tests. And yet, those tests we not able to catch the defects. Something was obviously wrong. This prompted us to dig a little bit deeper. If a method had 100% code coverage, why was there a bug. What other kind of tests would help us detect this bug earlier?
Consultants
In hindsight, almost every defect can be reproduced with unit test. External conditions can be simulated, so can various failure modes by using test doubles. However how realistic is this in developers’ day job? Some consultants will try to convince you that unit tests are the only true way. But this is far from our reality (and the data we collected). Obviously, consultants also have to eat and will try to convince you that what they preach is the best. Just take it with a grain of salt and run your own experiments to gather information.
Our Methodology
In order to determine which types of test (unit, API or UI) had the highest chance of catching a defect, we collected two pieces of crucial information.
The first one is the place where the defect manifest itself. This is the location where a defect is observed. We use the defect description, but usually dig a little bit deeper to see where the defect can be observed initially. Most of the defects manifest themselves to the customer in the UI, but the cause may be corrupted database entry for example. So we look a little bit deeper. The location could be a method where an exception is thrown, or a database table row with incorrect data, or a misaligned UI element.
The second piece of information that we collect for every defect is the place where the developer fixed the defect. In the majority of the cases this is a single method/function in the codebase. We gather this information by looking at the commit for the fixed bug. (as noted above developers put the bug ticket id in the commit message)
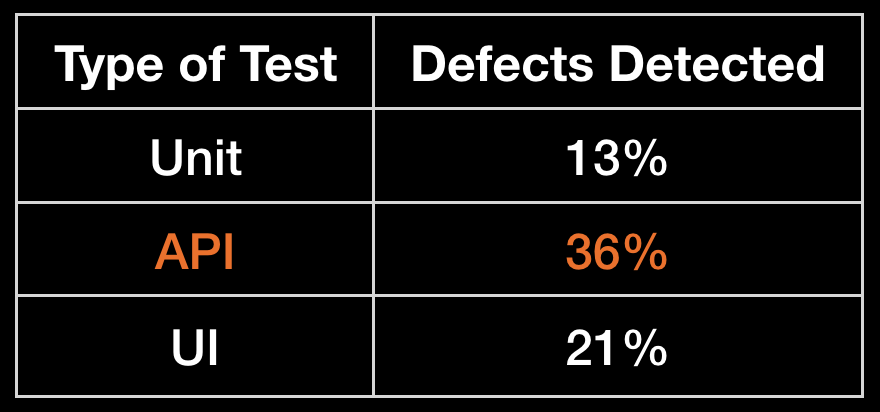
The most simple case is then the defect manifestation location and the bug fix location are actually in the same method or function or even in the same class. We consider that these defects could have been detected if only a unit test was written for the given method/function. 13% of the customer reported defects fall into this category. In the presentation there is an example of missing condition in an if statement that was causing an exception later in the same method. Had a unit test been written, this defect is trivial to spot.
If a defect manifestation location is in one class, but the actual fix is in another, then we consider that this bug could have been detected only by writing an integration test[5]. Those tests touch on a number of classes and methods, interact with network and the database. The higher you go in the automation testing pyramid, the more combinations you have. We also had to apply some common sense (we excluded corner cases and unlikely to think of scenarios) of how realistically it would be for an engineer to write a test that will highlight the defect. Like with the unit tests example above, in hindsight, you may speculate that the majority of the defects can be reproduced with high level tests, but — how realistic is this (we found to that 30% of the defects can not be realistically detected by any type of automated test)? By writing a simple API test, 36% of the customer reported defects could have been easily detected.
In the presentation there is an example of missing text encoding in a method that leads to a search function not working at all. The manifestation of this defect is first observed in the database where unencoded data is recorded. The fix is not in the database but in the method that should have applied the text encoding before it is being written to the database. This is a clear example of defect manifestation and bug fix located in different locations in the system.
Some types of defects require the UI in order to be reproduced and so only such type of automated test could detect them. For us they were 21% of all the cases. It is important to note two observations:
- If the defect manifestation and the bug fix for a UI defect are located in the same JavaScript function, we consider that writing a unit test for that function is enough to detect she defect. There is not need to create full UI test (using Selenium) to defect this bug.
- If the defect is in the backend and it is realistic to be detected by an automated API test (had one being written), then we consider this defect as an API detectable one.
For us, API tests are a clear winner. Why? It’s mainly because of the type software that we write. It is SaaS, that collects lots of data from the biggest social networks[6]. It then labels it, filters it and calculates various statistics. Our software does not contain much algorithms for data parsing, text extraction etc (those are very easy to test with uni tests). Integration tests that touch most of the system components are way more valuable than unit tests that cover only a single class/method and rely on test doubles. The majority of the bugs that we discover lie in the seams of the system, in the interactions between the different components. It is impossible to cover those cases with unit tests.
Modern Software
Modern day software applications have the following characteristic:
They are not monolith. The current applications are broken down to smaller pieces, which makes them easy to develop and deploy. The rise of microservices architecture is a testament of this trend. For example, our current application has more than 20 components that can be deployed separately (these are discrete components, and the count does not include cluster nodes). These components use web services to talk to each other. In order to test the whole system we need to have all of them deployed. And that's where the integration tests come in very handy.
They use 3rd party services. Literally for just pennies, you can get lots of data via different service providers - FX rates, weather forecast, social media feeds, process payments etc.. Another current trend is using functions as a services (lambda functions), that are hosted by someone else. In order to produce a working software, those 3rd party functions need to be glued together. Unfortunately, to fully test this type of code you need working end-to-end system.
They are complex. Software started as single programs, able to accomplish a specific task. With the invention of the high level languages, 3rd party libraries and open source code, the speed of development increases. With the event driven architectures and multi threaded programming the interactions between different components can explode exponentially and in unexpected ways. Those interactions are very hard to test in the carefully manicured environment of the unit tests bubble.
It's only natural then, that for some companies investing in integration tests makes a lot of sense. Integration tests usually use one of the two interfaces: web services or UI. Due to the fast changes in the frontend development frameworks (jQuery -> Backbone -> Angular -> React) and the changes in the user interfaces (desktop -> web -> mobile) maintaining reliable UI based tests is very complex and time consuming. But until recently we had no choice. Web services tests were not an option because most of the web based applications were rendering HTML in the backend and were serving it assembled to the clients. The only way to interact with an application was through its UI.
Ironically, the rise of the frontend frameworks that consume only data from the backend and construct HTML on the client side, made possible the more reliable web services test. The detachment of the UI rendering from the backend opened not just the possibility to test bellow the HTML layer. It also enabled complete testing of the rendered UI with detached backend (e.g. when the whole backend is simulated).
As long as you do not change the web service endpoints in a significant way, the API tests require surprisingly little maintenance. At the current company that I work for, the API tests that were developed 4 years ago are still running. We’ve completely rewritten the frontend once, developed two different versions of a mobile app and replaced the backend language (from PHP to Java) using the strangler approach. Unit tests for the PHP backend were no longer useful, but the same API tests, testing the business logic that did not change, continued to provide value and detected bugs that we introduced when we rewrote the backend.
The Problems with Integration Tests
The purpose of any type of automated test/check is to help us identify a potential problem as fast as possible. But if the integration tests are so awesome in helping us with this, then why aren’t they widely used? Well, for starters there are three major problems that need to be resolved.
Integration tests are slow. To get the maximum value of any type of automated test, it needs to run after every system change (code, configuration, database). Unit tests are the ideal candidate for that because they run in milliseconds. Integrations tests run orders of magnitude slower. Of course, API tests run faster than UI tests, but if specific measures are not taken they are still not suitable for execution after every system change. You have to aim to run all your automated tests (not just unit), after every single change, for less than 3 minutes. More than that, and the developers get distracted and get out of the flow.
Integration tests are unreliable. Unit tests run in a bubble, in a predefined and deterministic environment. Integration tests on the other hand, run on a fully operational system with lots of factors outside of our control. A number of moving parts may interact in unpredicted ways. To be useful, those tests need not only to be fast but to be deterministic. They should not fail for random reasons. Run them 100 times on a system that does not change, and they should pass 100 times. Shameless plug: I’ll be giving a talk at Agile Testing Days 2017 on how to make your integration tests more reliable.
Integration tests cannot pinpoint the location of a defect. Then a unit test fails, you have pretty good idea where and why the failure occurs. A good unit tests will execute a single method and if it fails, it’s either because an exception is thrown or because an assertion fails. You have a pretty good idea where this happens in the codebase. Now compare to what happens when an integration test fails. If it’s a UI test then an HTML element might be missing, if its is an API test then you may get 500 internal server error. Either way, that is hardly the information we need to pinpoint what and where the problem is.
How to Solve Them
In 2016 at Google Test Conference, I made a presentation how we solved the above mentioned integration tests problems. Here you can find the video and the slides. Extended slides version from VelocityConf is here. Bellow you can find some additional notes.
Integration tests can be divided to two kings depending on the interface they are using - API or UI. API tests are inherently more stable as the medium they use is made for machine consumption (HTTP and JSON/XML). The UI tests medium is made for human consumption. The majority of the UI tests can be broken to API and unit tests.
This division is very helpful because for most applications, the backend is where the business logic is located. No need to fire a heavy Selenium test if you can achieve the same result with lightweight API test. The same is true for testing a dropdown menu in the UI. No need for a heavy Selenium test that expects the full system to be deployed. You can either test it with a unit test or stub the backend completely if you still wish to use Selenium. Only a really small numbed of full UI tests should remain that make sure that all the parts in the system are wired correctly.
Almost all modern day applications connect to some 3rd party web service (social networks, payment services, realtime notifications). To achieve fast and reliable integration tests when you have a system outside of your control, you need to be able to stub/mock/fake its responses. The industry adopted term for this is service virtualization (I don’t like it and think it is a fancy title for something so simple). At my current company we developed our own to completely isolate us from the slow internet, social networks limitations and outages.
Stable and reliable integration tests require a dedicated environment to run on. This way, you’re shielding the running tests from random events such as: cron jobs, developers pushing new code, changes to the DB etc. If possible, use containers to emulate your production environment. Our test environment consists of 20 containers, each having a single purpose. They are restarted before every test suite, all of the tests data is also cleared. Only the source code of the application is replaced with the one from the current commit that we want to test. Obviously, it’s not the same hardware, and not suitable for performance tests, but it has all the components as the production environment and they are configured the same way. If some of the systems you’re integrated with are too old or otherwise impossible to containerize (e.g. a mainframe), use service virtualization to simulate it.
The unexpected benefits
Since integration tests require fully operational system, we can use them as an early indicator, as a weak signal amplifier for all sorts of potential problems. After each test suite execution completes, if there are no test case failures we can do a number of additional checks:
All the application and container logs are examined for exceptions and errors. A test case may cause a backend exception but, if that exception not manifested in the API/UI level, the test will not know about it and it will happily pass. Most of the time, this behavior caused by bad programming practices — e.g. catch an exception, log it, but then continue as usual. Also note that since those integration tests run in parallel, it is not possible to check for exceptions after each test case concludes. It’s impossible to determine which one of them caused the exception while they are running. So the exceptions check needs to happen after all the tests complete.
All databases are examined for unexpected/wrong data. Once we had a problem with our production environment. Out of the blue we started running out of memory and once that happened our application crashed. This happened three times in a row before we figured out what was the problem. In our database we have a column with Twitter IDs for which we collect data. The ID is an integer with value 1 or greater. 0, while valid integer is not a valid Twitter ID. However it turned out that one of the entries in that column was 0. The backend was written in PHP and because of its magic type conversion capabilities, 0 equals false. This would cause an eternal loop which would consume all the machines’ memory. Long story short, we now implemented a self system check and repair for such incorrect data (as SQL data types are not fine grained enough). And while this check is straight forward for SQL databases, we get the biggest bank for our buck with unstructured data in NoSQL databases.
The status of the containers. After the test suite passes we check for the status of the container. Sometimes there is a crash, but no errors or exceptions in container logs.
Measure performance impact of any commit. The only thing that changes between test suite runs is the source code. We can take various performance metrics for each commit and compare them to the previous ones. Does this commit improve the performance or makes it worse? Some of the metrics to collect are: the time it takes to complete all the test cases, the size of the log files, max memory or CPU consumed, swap usage size, disk i/o operations count, network traffic sent in/out, garbage collection stats, the number of database operations, also various database performance statistics, cache hits/misses.
Conclusion
For a while I thought something was not right with our results - preferring integration over unit tests. It turns out that other people start to think this way. Similar articles came out in the last weeks - here and here.
But take my words with a grain. There are no universal best practices. Go and see. Experiment and measure for yourself. Think.
I’ll also be giving this talk in November 2017 at ISTACon ↩︎
For the purposes of this article, API and web service tests will be used interchangeably ↩︎
Usually REST, in older app this could be XML ↩︎
I'll be talking about how to improve such tests at Agile Testing Days 2017 talk called 'No More Flaky Tests' ↩︎
Integration tests can either be API or UI ↩︎
For example, we make more than 10M requests to Facebook APIs every day ↩︎