Keep External Dependencies Under Control
Two months ago, we were moving production servers from one datacenter to another. It was supposed to be boring, no-thrills event. There was no new code to be deployed, only running it from different location. We were pretty confident, that there would be no problems, partly because we’ve migrated and tested our internal test environment to the same location a couple of weeks ago. Nothing could go wrong, right?
So we were “mildly” surprised when all hell break loose, after we started the servers in the new datacenter. The system was responding normally in the first 5 minutes, and then started slowing down more and more. Eventually, it halted completely and we had to switch back to the old datacenter until we figure out what was the problem.
After a couple of hours of diagnostics and we found the culprit. We’re using StatsD extensively to track all sorts of statistics. Each second we’re logging between 100 and 500 events. Because of the high volume, we had hardcoded the IP address of the StatsD server in the /etc/hosts files, so that there were no DNS queries to resolve it (which makes the whole process faster).
When we moved to the new datacenter, we did not want to have hardcoded IP addresses in /etc/hosts files because it makes it harder for maintenance. What happened is that we accidentally DDoS-ed the DNS server with requests to resolve StatsD server address. This in turn slowed down all the other resolution requests made to the DNS server, hence the whole system slowed down significantly. As the old saying goes:
The operation team figured out how to solve this problem, but for us, engineers a red light went on. In case of similar emergency in the future, we did not have any way to temporary stop logging to StatsD. All calls to StatsD were made by using their library API directly:
StatsD::increment('sys.methods.twitter.comments');
To make matters worse, we had 300+ such calls:

There was no way to disable StatsD logging at once, if need be. So we decided to setup a simple thin wrapper around the external API StatsD call. Now we have the ability switch on/off the logging ability from once place in the codebase.
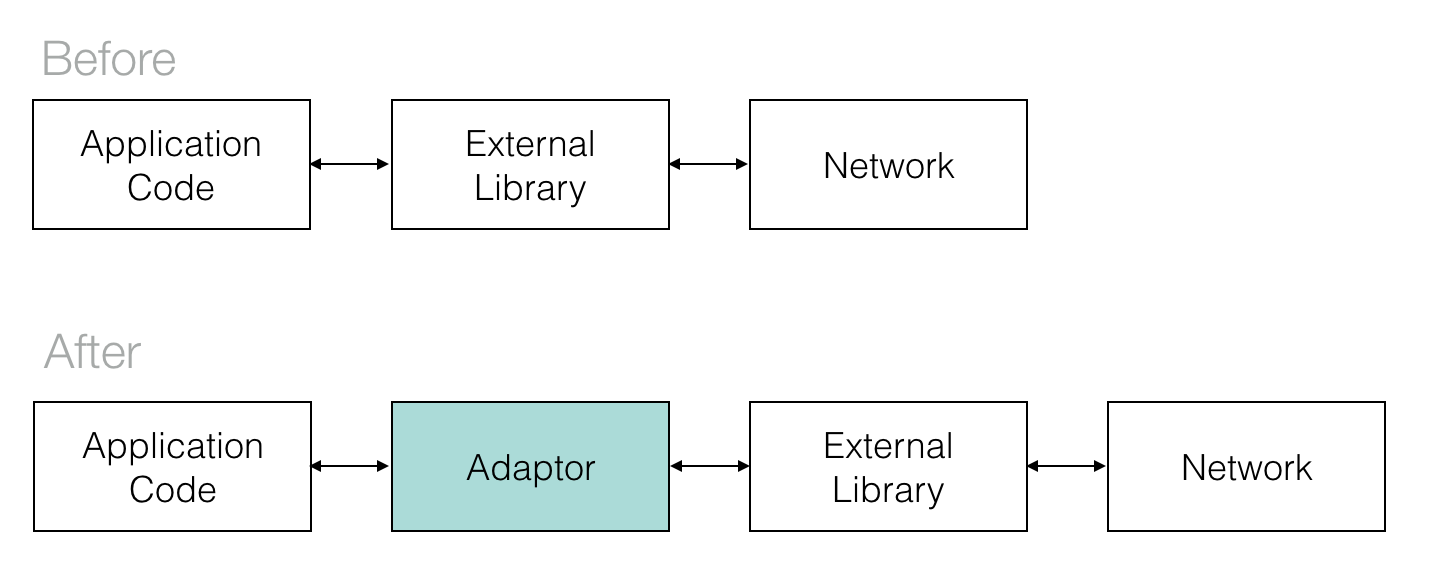
Wrapping external dependencies in thin wrappers in order to tighter control over them is not a new concept, of course. Depending on how it’s implemented, this pattern has different names: adaptor, facade, shim or just wrapper function. It is mostly used in order to mock/stub the external call for unit testing purposes. However, it has even bigger benefits in terms of application resilience, maintenance and testability. If you haven’t wrapped all of your external dependencies yet, I think the reasons listed bellow will persuade you to do so.
Unit Testing
This is the original purpose why this pattern was invented. Remember that your unit tests should not touch the network, any databases or filesystems. Lets assume, in PHP, you want to unit test a method that uses file_get_contents(). It reached out over the network to read a file. The only way to write reliable unit test is to wrap file_get_contents() in a small method, and call this method instead. Then in your unit tests, you would overwrite the small method with your stub/mock and simulate whatever behavior you want — file found, file not found, internal error, timeout.
Before:
$file_contents= file_get_contents($file_url);
After:
function fileGetContents($file_url)
{
return file_get_contents($file_url);
}
$file_contents= fileGetContents($file_url);
Replacing Libraries
Imagine that in the scenario described above (the 300+ direct calls using StatsD PHP library), we want to replace StatsD logging with another logging framework. If you don’t have an adaptor, you need to changed to code in 300+ locations. If you have an adaptor, you need to change the code only in once place.
Logging
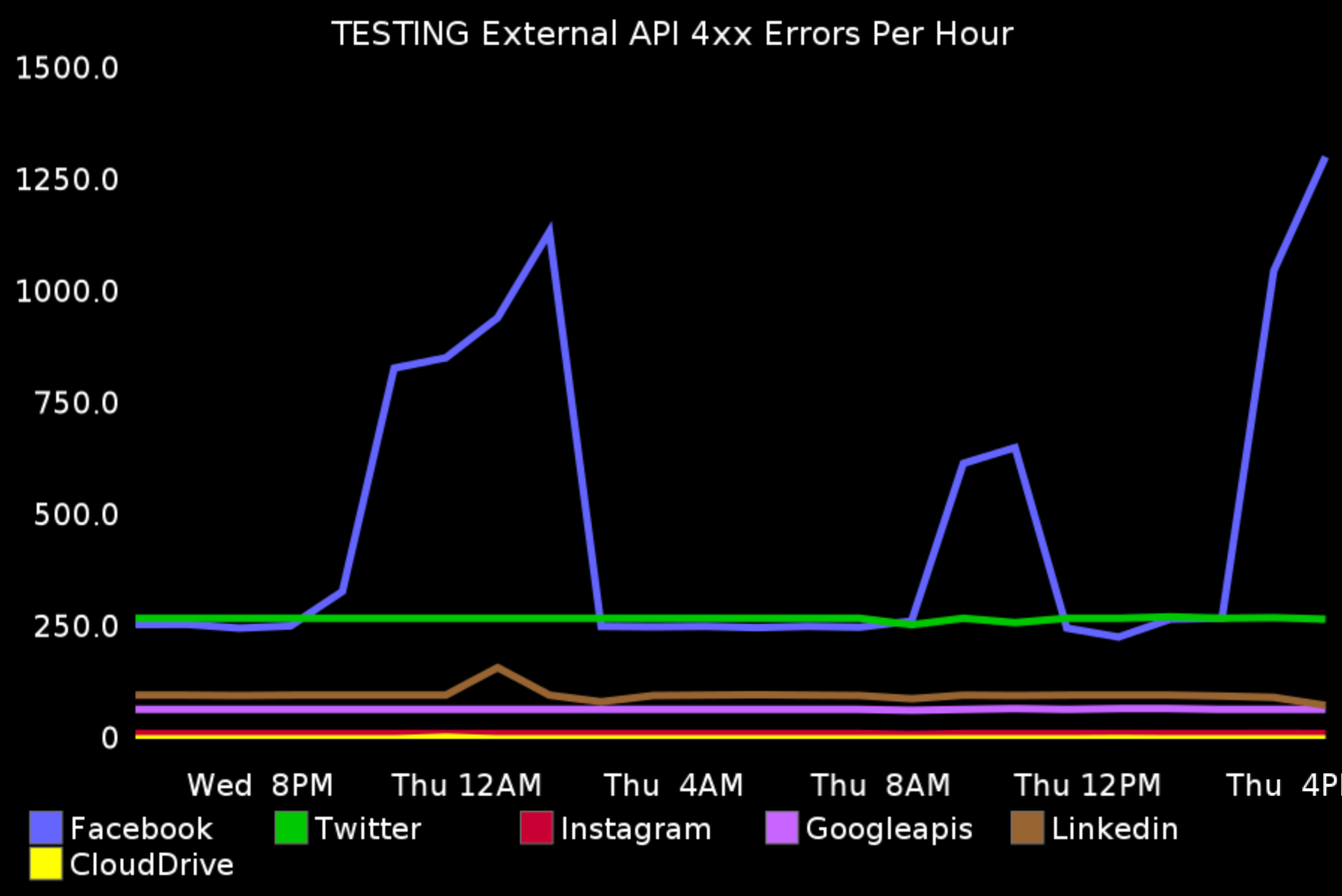
When all the external requests do through one adaptor, it easy to keep track and log them. For example, you might use Facebook’s library to post messages. With the adaptor, you can track how many calls you made, how much time it took for each one, how many HTTP errors you get (4xx, 5xx), have you reached your API limit etc.
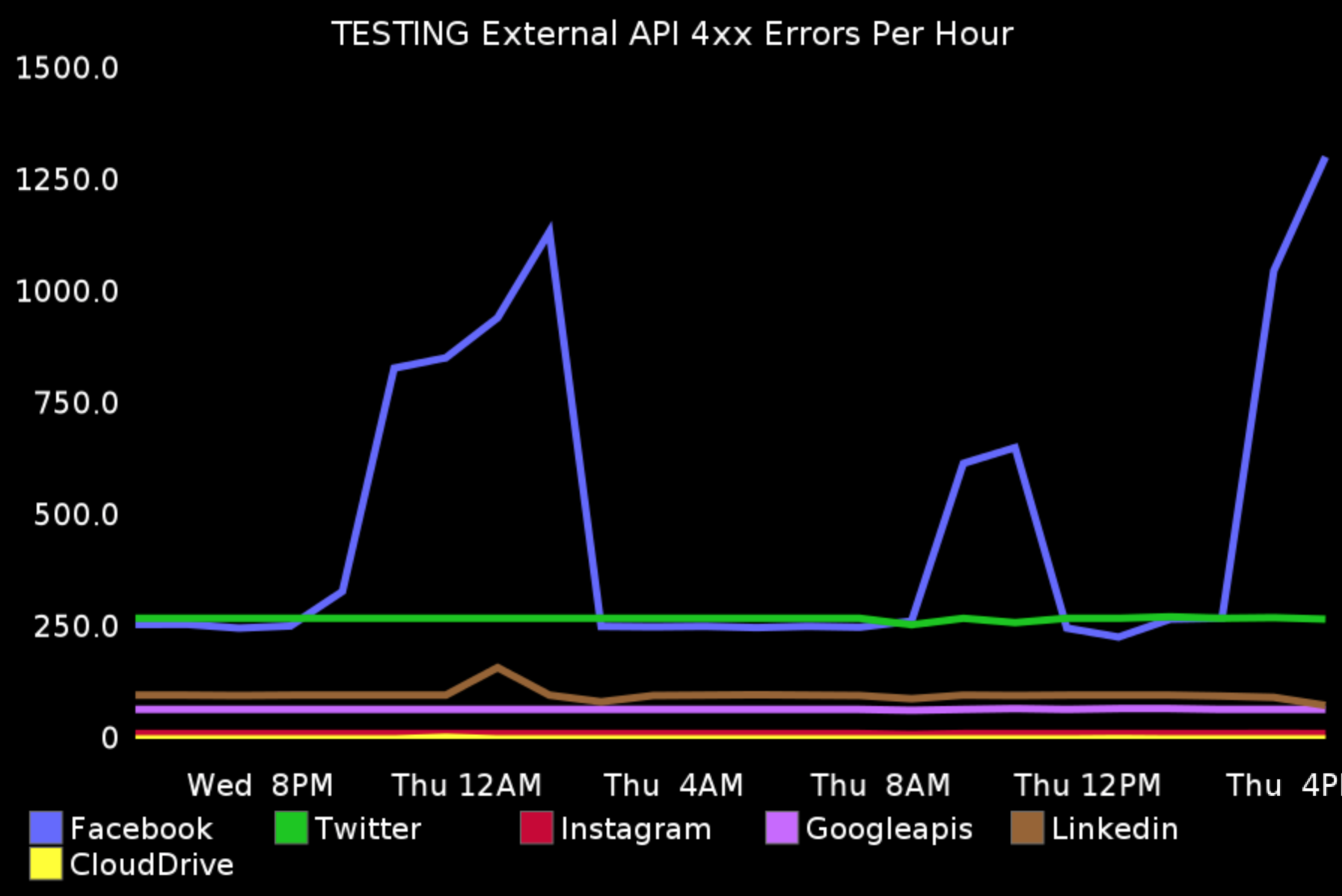
Emergency Stop
In case something goes wrong, you can immediately stop all the calls to the external services in the adaptor, instead of everywhere in the codebase.
High Level Testing Stubs
Lets suppose your app is using an external service to make a payments with credit cards. If you have an adaptor over your payment provider library*, it can greatly benefit your high level tests (any tests that are not unit). Those tests may be manual or automated. For example, you may not want to contact the real payment provider for a test that spends real money. In your adaptor you can create ‘magic’ credit card numbers for testing purposes:
4242 4242 4242 4242 -> always allow the transaction
4646 4646 4646 4646 -> fail with insufficient funds
4848 4848 4848 4848 -> fail because of bad CVV
3838 3838 3838 3838 -> blocked for fraud
if(strstr($cardNumber, '4242424242424242') != false)
{
return 'transaction success';
}
else
{
return $this->contactThePaymentProvider($cardNumber, $amount);
}
Be careful though with those ‘magic’ numbers. You need to have some safeguard for that those numbers cannot be used in production.
Similarly, if your app uses social media, you might want to do high level tests of that will happen when Facebook is down, or reject your new post.
Note: Most of the payment providers these days provide a test environment, sometimes called sandbox, to play with. The problems that I’ve seen with such environments are that they may not support all the responses you need, they are being treated as second class citizen and not maintained well (sometimes not accessible for hours). They are slow for test automation purposes because are the traffic goes the internet. Also it requires you to switch between environments to test your app with real transactions.
Error Detection Logic
Adaptors help you to have all the error detection logic for the external library you’re using in once place. For example, you might want to catch and/or re-throw exceptions based on that HTTP error code you get. Or maybe you want to perform some specific action every time an empty response is received. Again, you have all this error handling logic only in the adaptor and not scattered everywhere in the codebase, avoiding code duplication.
Converting Incoming Data
Most of the time, you need to do some type of data conversion. The data you receive from the outside world needs to match your internal domain representation. You may want to filter some of the received data out, to convert binary to text, XML to JSON and so on. These are technical details that need to be in the adaptor. They should not leak into the upper abstraction layers that deal with business logic. You should not mix the low level technical details and high level business logic.
Retry Logic
If the external library you’re using requires network to send or receive data, then you can greatly benefit from retry logic in your adaptor. Internet may be slow or unreliable, the remote service maybe sketchy and sometimes throw internal server error. The majority of the time, these are transient errors. They go away if you retry again later. You will increase your app resilience if you implement some sort of retry logic for your external communication. For example your app might send SMS through a gateway, retry on HTTP code other than 200 or 403. Simplified version:
$retry = true;
$numberRequests = 0;
do
{
$numberRequests++;
$sms->send($text);
$httpResponseCode = $sms->getLastHttpCode();
if ($httpResponseCode == 200 || $httpResponseCode == 403)
{
$retry = false;
}
} while ($retry === true && $numberRequests < 3);
You need to be careful to distinguish which errors are transient and which are permanent and retry only the former. It makes no sense to retry authentication or forbidden errors, as you most likely need to change access tokens, or permissions. It makes sense to retry internal server errors and timeouts. Retrying not found errors depends on what your application is doing. If it’s uploading a file first and then verifying that the upload is correct, then it makes sense. However if your application is checking the weather for an airport with the three letter code (e.g. MAD for Madrid), not found errors most likely means wrong airport code and retrying the request will only make your app slower.