Running Test In Parallel - Optimal Number Of Threads
June this year I presented at expo:QA conference. It was a case study on how we increased the execution time of high level automation tests more than 60 times . Last week I received an email from one of the conference attendees, asking for additional details on two specific topics from that talk. I think the reply will benefit a larger audience as well, so I decided to post it publicly. It’s a bit long and it is split it in two logical parts. This is part one. The question was: “When running tests in parallel, how do you decide what is optimal number of threads?”.
Before The Start
When most of the companies decide to speed their automation tests, the first thing they do is run them in parallel. However this is the last thing you should do, and only when you have exhausted all the other improvement options. Why? By running tests in parallel the execution time shrinks. All the other improvements compared to the gain of the parallel tests seem insignificant. You may mistake the small improvements with random variation, so it’s not easy to track them. Their ‘gain’ is split between the threads. Essentially, running tests in parallel first, makes it really hard to spot other potential improvements (such as those that lead to more stable tests).
Self-sufficient Tests
In order to run tests in parallel, you need to do some upfront work. The tests should be independent of each other. They should be able to run in random order and pass each time. Each test should be idempotent (when you run it 100 times, the result should be the same each time). Each test must create all the test data that it needs — users, accounts, transactions, etc. Ideally this should be done using the official API services of your application, before the test starts. If not available, then you might use unofficial APIs, created and used only for testing purposes. Your last resort would be to insert data in the DB, either directly or via stored procedures. The tests should not rely on any shared data. The only exception should be configuration data that is considered static — e.g., the list of countries in the world, the list of currencies, the timezones.
Tests Not Suited For Parallel Runs
In some cases, a test may require a change of configuration data that is shared with a number of other tests. For example, a test may require that all transactions coming from Germany to be blocked, while the rest of the tests require that all transactions coming from Germany to be allowed. This situation is normal and one solution is to separate the tests that modify a global configuration in a new test suite. You can run all the "parallel safe" suite in one go, and when they finish, you can start the "parallel unsafe" suite. The latter tests should be run sequentially only. At the end of its execution, each test should reset the global configuration back to its original state.
Running Experiments
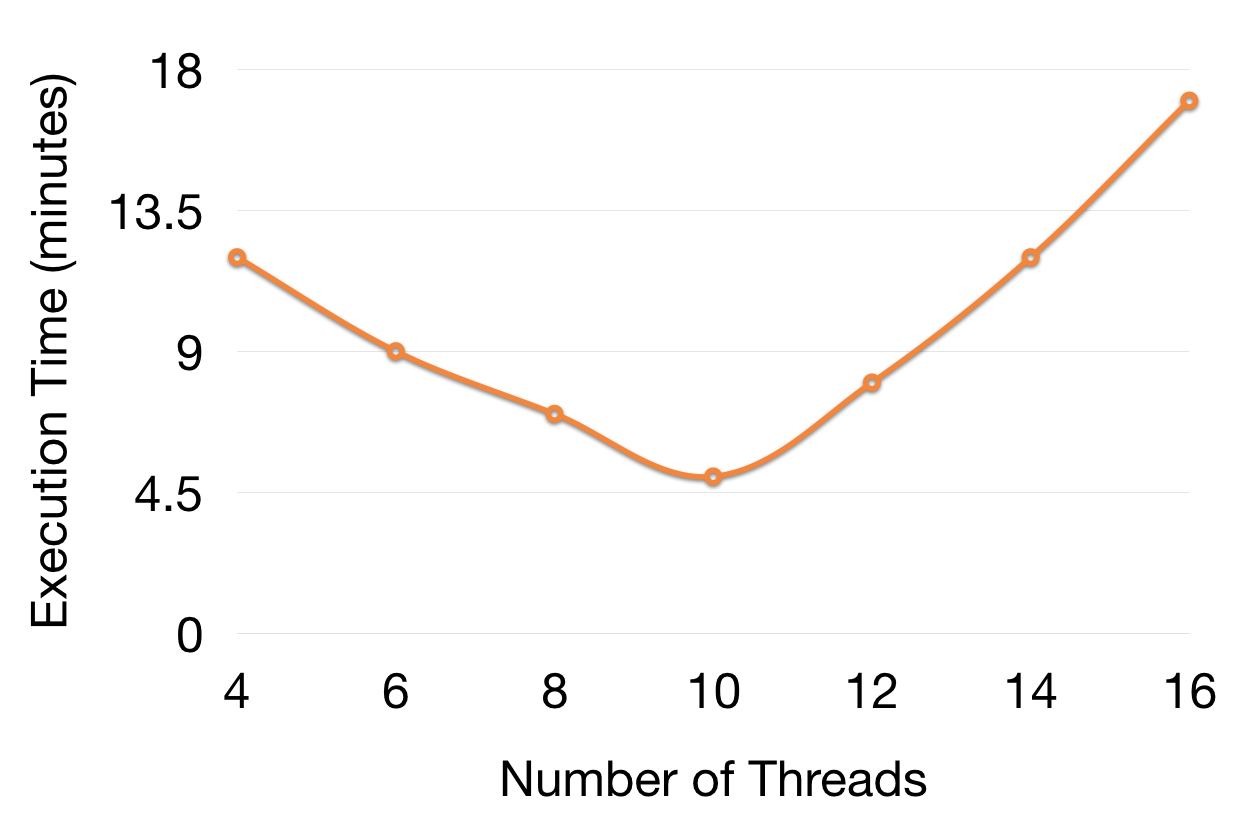
Only when all of the prep work is done you are ready to run your tests in parallel. In order to figure out what’s the optimal number of threads, you need to run some experiments. Run all the tests in one thread and record the execution time. Next, run all the tests in two threads and record the execution time. Next, run all the tests in three threads and record the execution time. You get the idea. Increment the threads with one and write down the result. We get pretty conclusive results when testing with threads between 1 and 20. After you have the results, it should be pretty easy to spot the minimum execution time and the corresponding thread count. If you graph the results they should look like this:
The Law Of Diminishing Returns
At some point after the minimum execution time, the more threads you have, the execution time starts to grow. The law of diminishing returns kicks in. You hit a bottleneck in the system, because all of the threads compete for limited resources. Something has to give at such speeds. For us this was the database. Lots of threads need to read and write form a single database and this caused locks and delays at higher thread counts.
Memory Bottleneck
One of the first bottlenecks that you’ll hit is the amount of memory on the machine where the tests are executed. Our tests run all in memory (even the databases, a separate blog will describe this in details) and do no touch the disk. However, at some point the threads will eat all of the available memory. The operating system will start to use the swap on the hard disk to perform all needed operations. When this happens, tests will slow down significantly - you’ll definitely notice it. On linux, you can monitor the swap size with the 'top' command.

In this case, there is a small amount of disk swap used. Ideally you’d want to see this:

Just because there is a swap on disk, does not mean that it is used for your tests. In order to be sure, on Linux, you can run 'vmstat 1' command during test execution. Monitor 'si' and 'so' columns (swap in and swap out). If they remain 0, no swap is used.
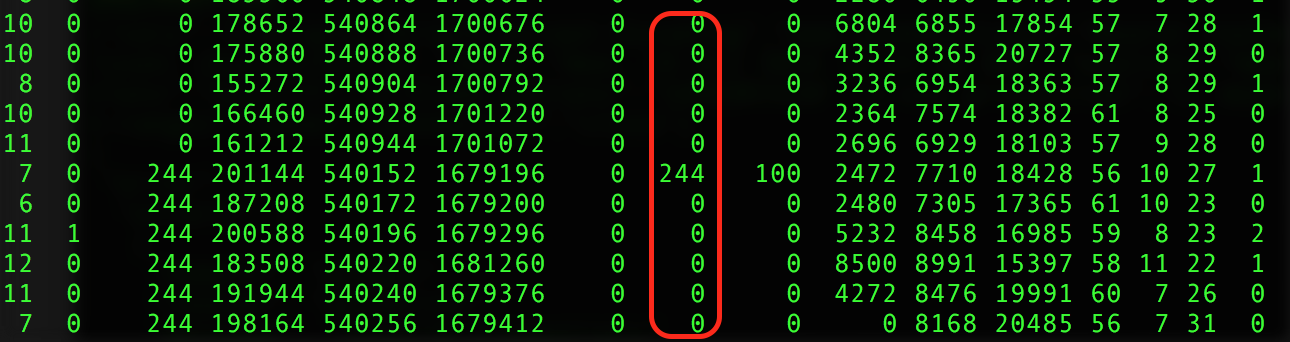
If you see swap usage in your tests, you need to add more memory. Nowadays pretty much no one runs tests on bare metal machines. Virtual infrastructure makes it easier to provision the machine with more memory when needed. Then just reboot it so that the change can take effect.
Hardware Matters
The threads/execution time graph is valid only for specific hardware configuration. If you move to another machine, or upgrade the CPU/memory, you need to run these experiments again to determine the new optimal thread count. When we started our tests, initially the optimal number of threads was 10. Some months later, we moved the tests to run on more powerful machine. To our surprise, when we run the experiments again, the optimal number of threads was now 12.
Heijunka
The last note for running tests in parallel — the number of tests in each of the threads should be equal (approximately). When we started running the tests in parallel, we were using parallel_tests, thinking that it will divide the number of tests equally among the threads. However it divides equally the number of the feature files between the threads (if you’re not familiar, check here what are those files). Each feature file can contain a random number of tests. We had some feature files with 3 tests and others with over 50 tests. In order to have similar number of tests per thread, we had to manually split some of the big feature files to smaller ones. Why is equal batch size important? Because 'parallel_tests' will wait until the thread with the highest number of tests to finish, and then declares that the execution is over. If you have one big feature file, it will execute all the tests from that file in a single thread, even if the other threads are idling.
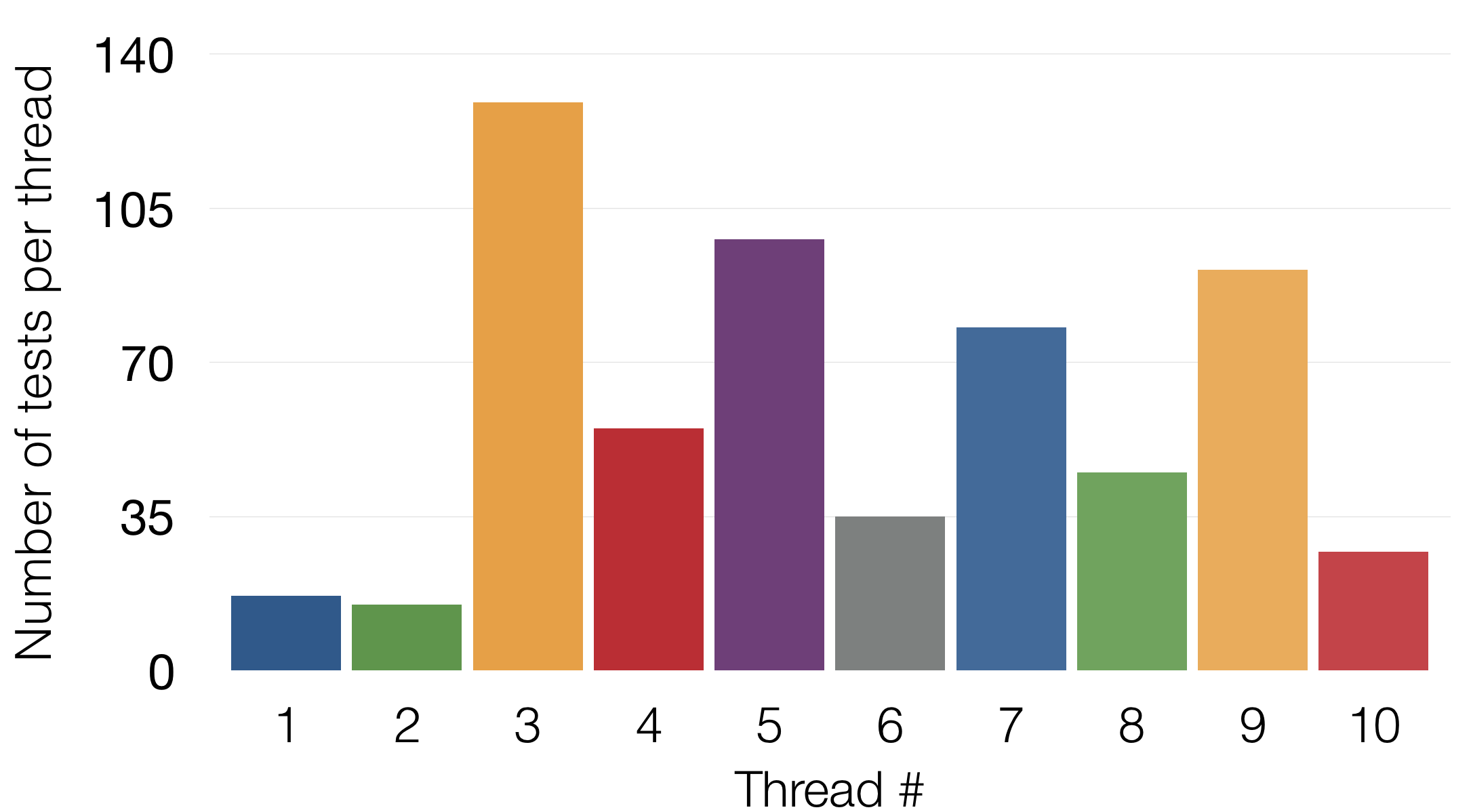
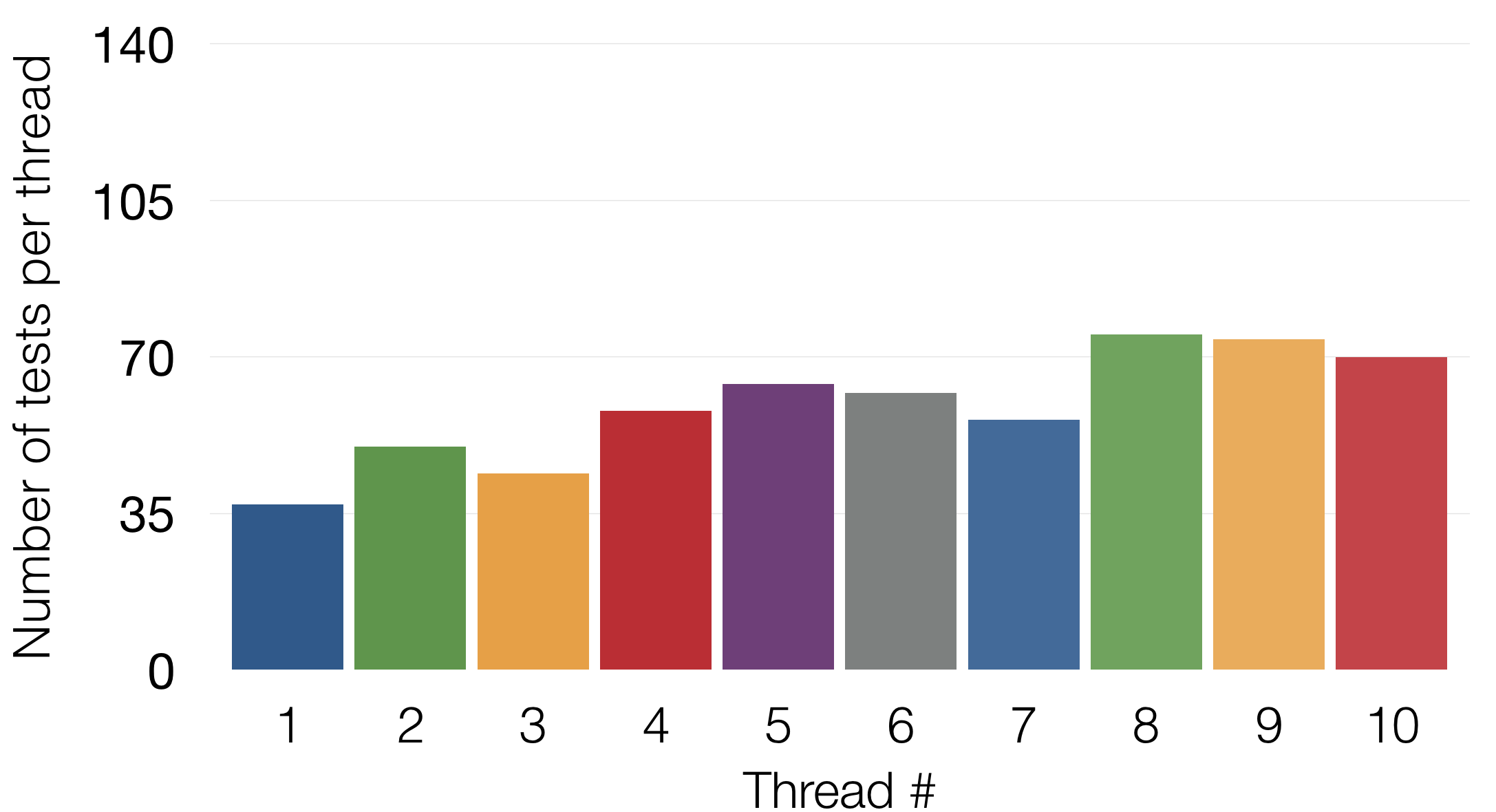
There is actually a Lean term for this - heijunka, although we use it a very straightforward and simple case.
For the initial leveling, we were counting the numbed of test cases by hand. However, because of the constant update of the tests, this approach was not scalable. So we wrote a small tool to calculate the number of test cases in Cucumber feature files. It uses methods build in the Gherkin gem to parse the files (if you are using Cucumber, you already have this gem installed). It also has the capability to ignore certain tags.