Remove Unused Code

The story of how Knight Capital went bankrupt because of a software bug is well known. In summary, the high frequency trading company (once the largest equities trader in the U.S.), lost $460M for 45 minutes on 1st of August 2012. On the next day the company lost 75% of its equity. This case has been the poster child for all sorts of debates about how much damage a software defect might cause and how good DevOps practices might have helped to save the day. However I want focus your attention to a detail that’s less, if at all, talked about, mainly because it’s good programing practice and not an operational one.
Complex systems fail because of combination of factors. There are three major problems behind this debacle (actually there are more, you can read the full SEC report for details). Knight Capital was installing a software update to their systems. It was supposed to be installed on 8 servers. Instead it was installed on 7. The operations guys somehow missed one server (the first problem). On the server that didn’t get the update, a normal condition caused execution of old functionality, not used for more than 9 years, instead of the brand new functionality. This unused piece of code should have been deleted long time ago (the second problem). The system then sent 97 emails to a group of employees, that indicated that the deployment has failed for that server and it was executing a functionality that should be disabled. No one payed attention to those emails (the third problem). In this post I’ll talk about the second problem, the unused code that’s lying around in our systems, and as seen in this case lead to a catastrophic disaster.
Examples of unused code:
- commented code
- comments that are irrelevant, obvious or just plain wrong
- a code that is never executed
- unused configurations
All of the examples above are considered a form of waste and it should be removed as soon as possible.
Commented Code
Why is it bad to have commented code lying around? When you look at a commented line of code, most of the time your mind starts to wonder - why is this line commented? Why is it not deleted completely? When was it commented? and so on. In some cases the commented code refers to variables what are long gone or with changed names. This further increases your cognitive load.
Comments
Code comments are technically ‘not a code’, but this does not matter. Your mind processes them the same as code e.g. tries to interpret and make sense of them. In case of code comments, they should bring you additional information that can not be expressed with the code itself. Some examples:
Do you need a comment to tell you where the class ends?
}// end of class
No need to keep revisions as a comment, that’s what version control software is for.
// ## Revisions
// * 2012-06-12 CAN Initial implementation
// * 2013-11-19 This list is not called directly anywhere
Don’t describe what can easily be perceived, Captain Obvious.
// call the parent constructor
return parent::__construct();
Of course most of the comments start with well intentions and work well together with the accompanying code. At some point however, the developer changes the code and forgets to update the comment. This goes unnoticed because if the code is wrong, there will be consequences. Not so true for the wrong comment. The next developers that looks at the code will read the misleading comment and will spend some amount of time trying understand the why the code and the comment contradict. This is waste. Better option would be to include the comment in the commit message. Assuming you write meaningful commit messages, they will be properly tied together to the piece of code. Change the code, the commit message is different.
Unused Code
While the waste in categories comments and commented code is easily spotted visually (most of the IDEs will paint the comments differently) in the case of unused (but not commented) code it’s not so easy. This is never used or never reached. Depending on the language you use (the more statically typed the better), there are static code analisys tools that will alert you if a piece of code is unreachable or if a method is never called. This is not 100% panacea though. Sometimes a functionality is deprecated, but the API is still exposed, though can not be reached by the UI. Or there are leftovers from feature toggles or from branch by abstraction.
Here again you can see the problem with waste and with the wasted brain cycles to analyze something that is never used. But this is the smallest problem. A bigger problem is that this code shows up if you do search and replace and when you refactor. This needlessly complicates those tasks. Even bigger problem is that this code can accidentally be executed when it shouldn’t (Knight Capital case).
So how can you detect such code? You need to instrument your codebase so that you know if a particular piece of code is called at runtime. This operation is preferred to be done in live, as some cases can’t be reproduced in test/integration/staging environment. After all, it’s your customers that matter. There are different tools for different languages to show you even graphically the execution path. You can easily spot pieces of code that are never used. The problem with such tools is that they may degrade the performance of your application by more than 50% on production and this may not be acceptable.
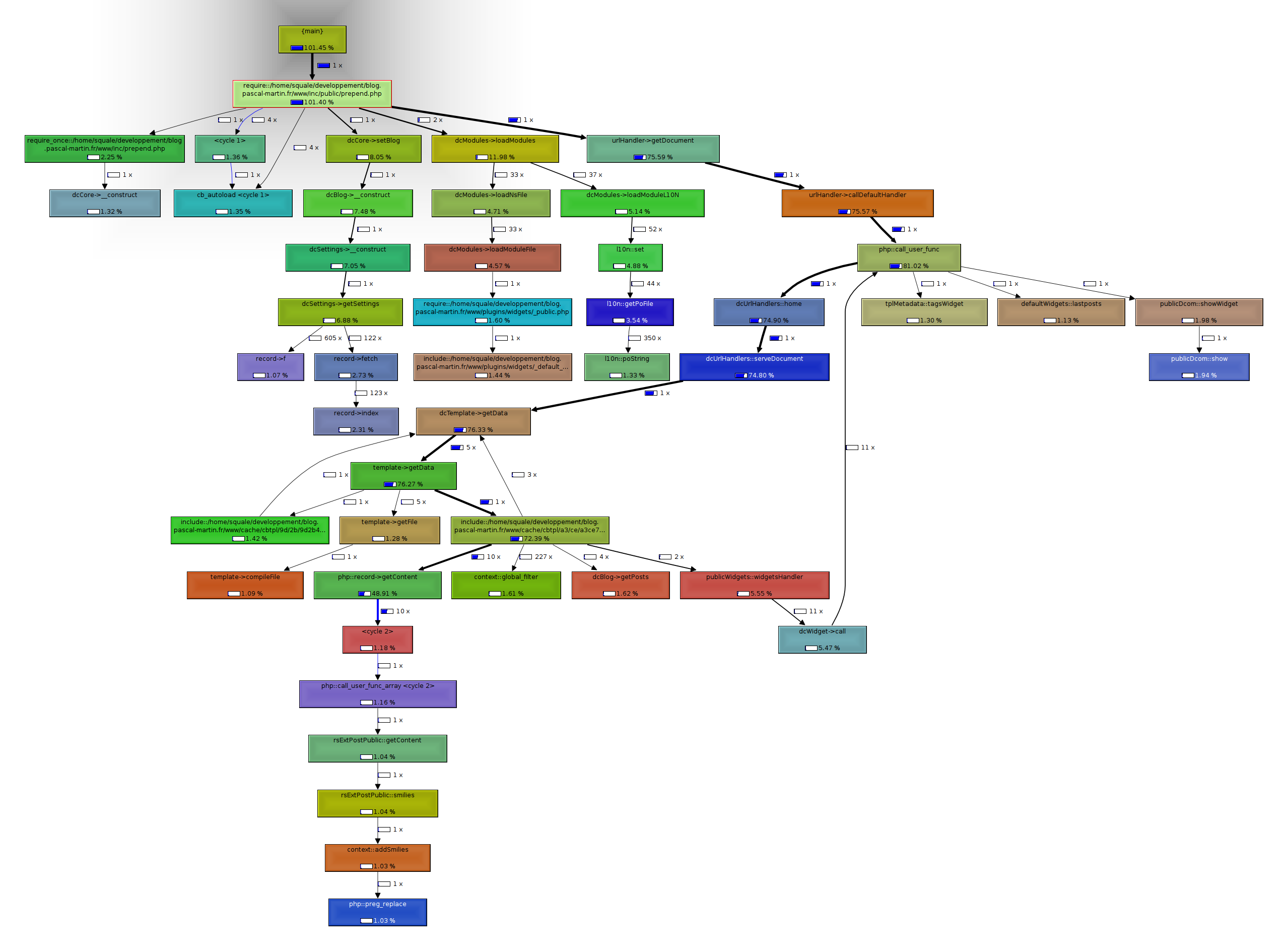
We were in such situation and we had to use a ghetto style approach that was low tech, but caused no performance degradation in production. We manually added a call to statsd to increment a counter when a class was instantiated:
$this->statsdIncrement($className);
StatsD uses UDP so it’s fast and you don’t have to wait for confirmation. Then we looked at the graph and confirmed which classes were never instantiated and then we deleted them.
Unused Configurations
Those can be in yaml files, JSON, XML. All of the above mentioned concerns apply.
Result
Removing unused code will result in smaller code size. This in term will produce faster compile time, faster execution time, faster static analysis, faster and reliable code search and replace.
Removing unused code is no brainer, as soon as you encounter it you should delete it. Better ask for forgiveness than permission. And remember all the changes are still kept in your version control history. They are not lost.