The Goalkeeper's Impact
At Falcon.io we believe in empowering our teams and in their self organization. There are few top down technical mandates (e.g., use Java for backend, services should not run with root privileges). There are even less organizational mandates and ceremonies.
So it’s up to each team to decide how to handle issues reported by our customers. Some teams put those items in their backlog and dedicate a certain amount of time to fix them. They are being pulled by any developer on the team.
Other teams have what we call a “goalkeeper”. The team is doing a rotation every few weeks and dedicates a single developer whose only job is to work on issues reported by our customers. If there aren’t any to investigate then this person is working on the new features.
In the end of August 2021, one of our teams decided to have a “goalkeeper”. The main reason was that we stared seeing customers complains more about how long time it takes to investigate or fix a bug.
The team has 5 backend developers. My first thought was that if we have a "goalkeeper" we will produce 20% less features or velocity will suffer or both. But customer voices grew larger and larger, and we couldn’t see any alternative.
How did we do?
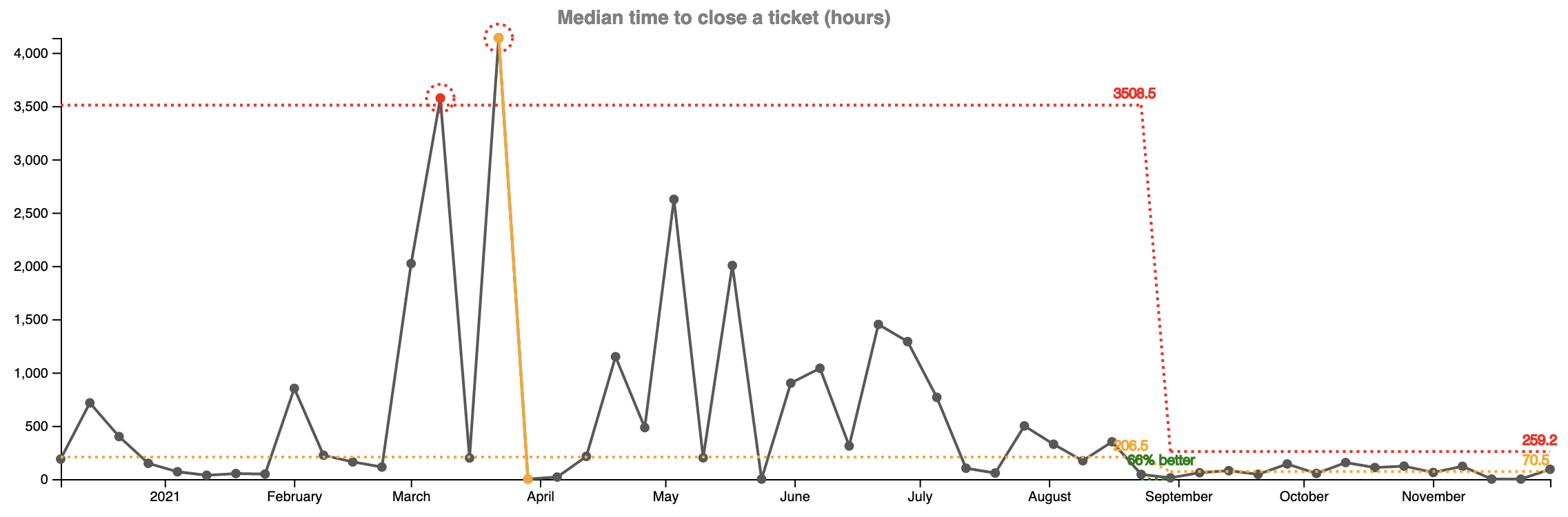
First let’s take a look at the time it takes to investigate and close a customer reported issue. Until we made the change in the end of August the median time to close a ticket was 206 hours. 14 weeks after the change the time had improved by 66% and is now 70 hours.
Not all tickets end up as hot fixes though. Most of the tickets (around 75%) are investigations that do not require any changes to production. We specifically track how much time it takes us to produce a hot fix to production. For this team the median was 70 hours before and 5 hours since we have the “goalkeeper” (94% improvement).
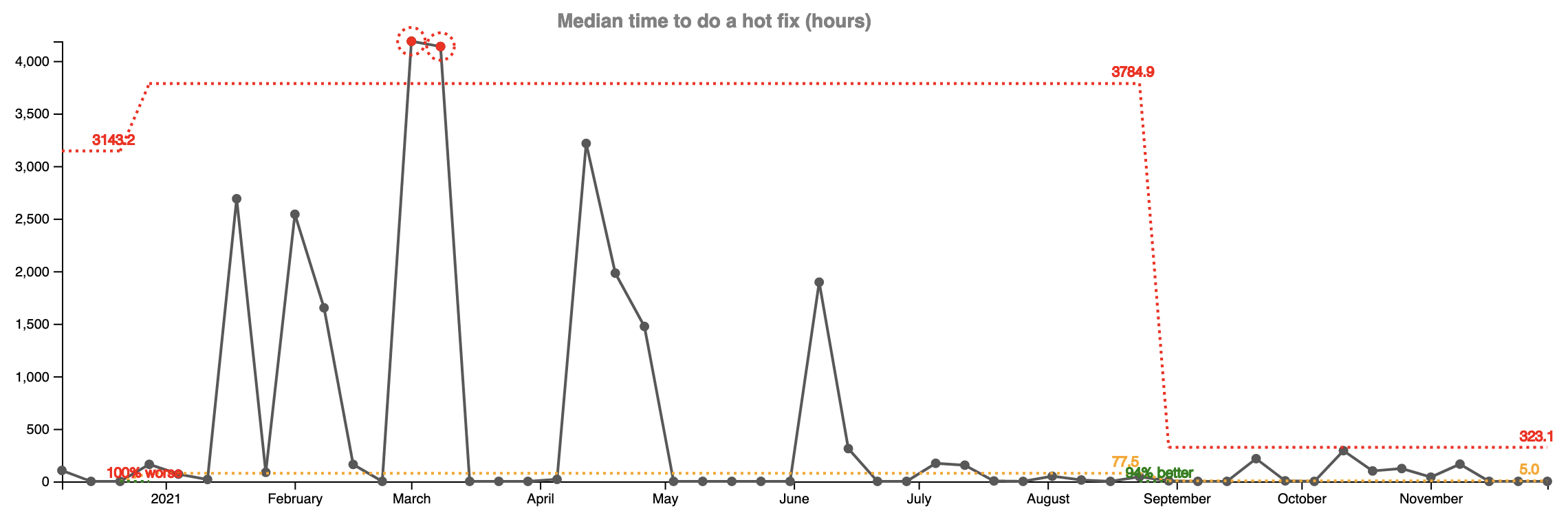
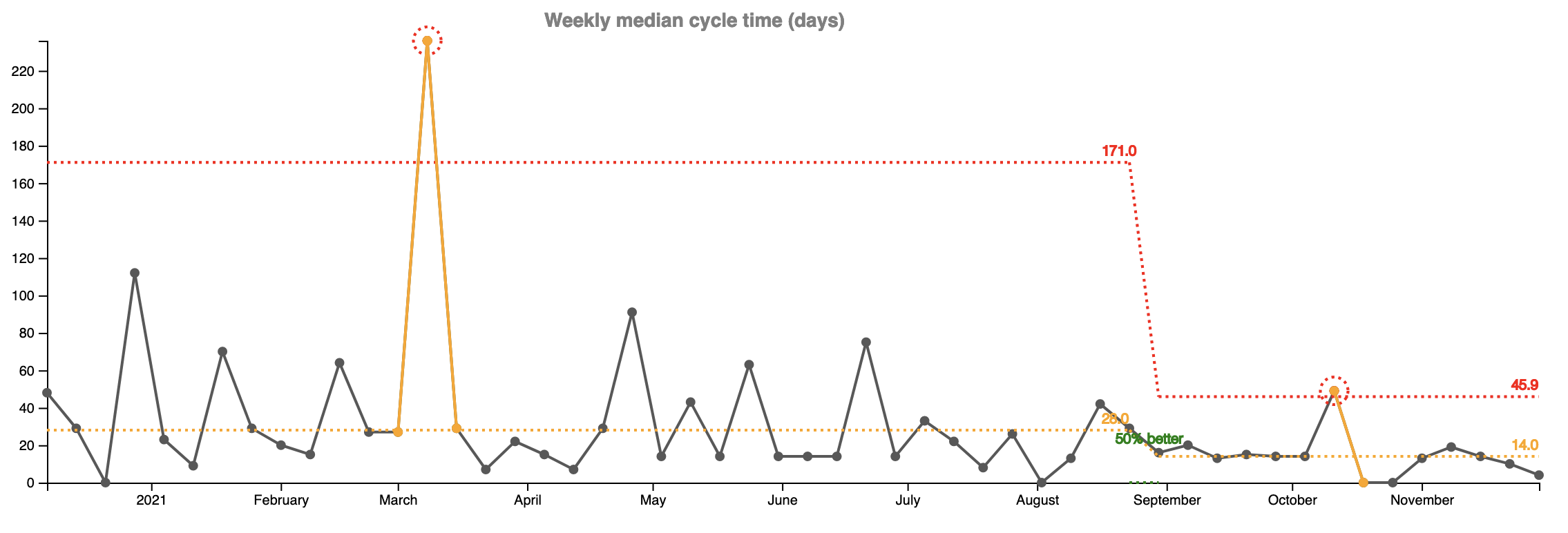
But there is something even more important. In the two graphs above you see some big swings and inconsistencies every week. They made it very unpredictable for our customers and our support team. Resolution times were varying wildly depending on how much time we could spare from new feature development to do investigation and bug fixes.
The variation is way less in the last 14 weeks and it’s easy to see on the graphs as wells as from the upper control limit (the red line).
OK, one last graph on customer complains. It shows the currently open count of tickets (our work in progress - WIP). Since the beginning of 2021 it was constantly going up. We neglected investigation of customer reported issues so that we could work on new features. This could not go on forever. Since end of August there is a sharp decline (58%) of the open tickets for investigation.
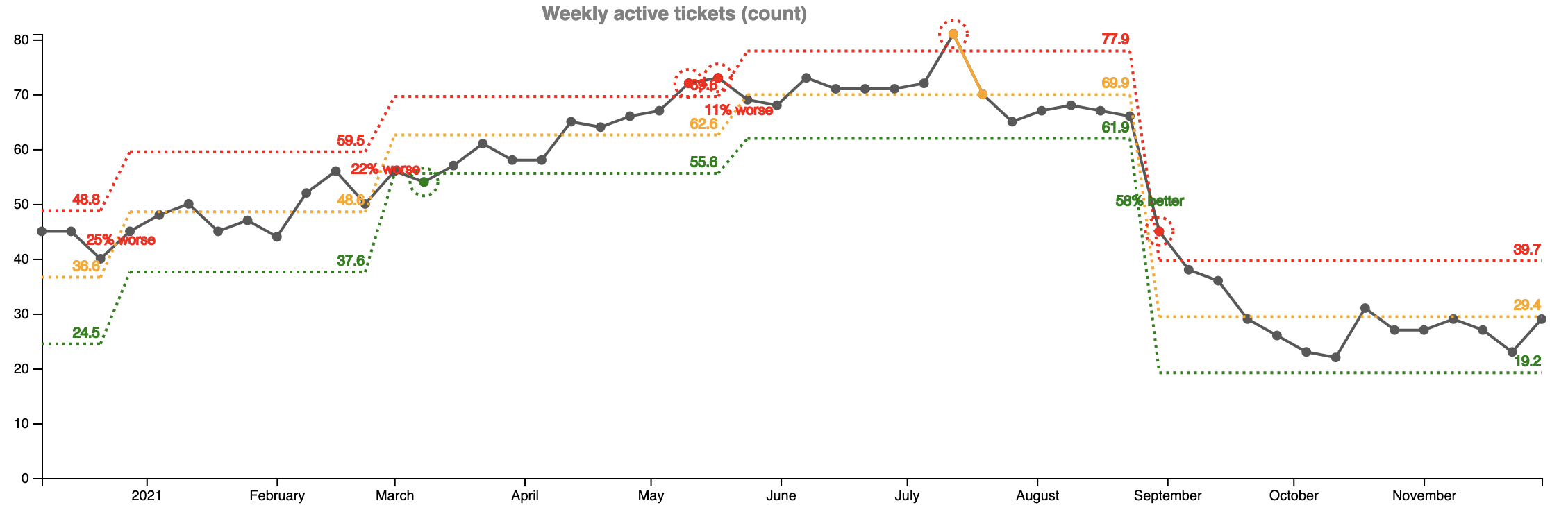
In the book The Principles of Product Development Flow, Donald Reinertsen describes how a queue size is a leading indicator of the cycle time (how much time it takes us to resolve an issue). The more WIP items we have, the more time it takes to resolve them. The book is not an easy read but it’s fascinating. I highly recommend it.
Right, but these improvements are to be expected because we now have a dedicated person to deal with them. Now let’s go back to my initial worry that having a dedicated person to work on customer complains will reflect on our ability to produce new features. My estimate was 20% negative impact as there are 5 developers on the team. Did we get any worse?
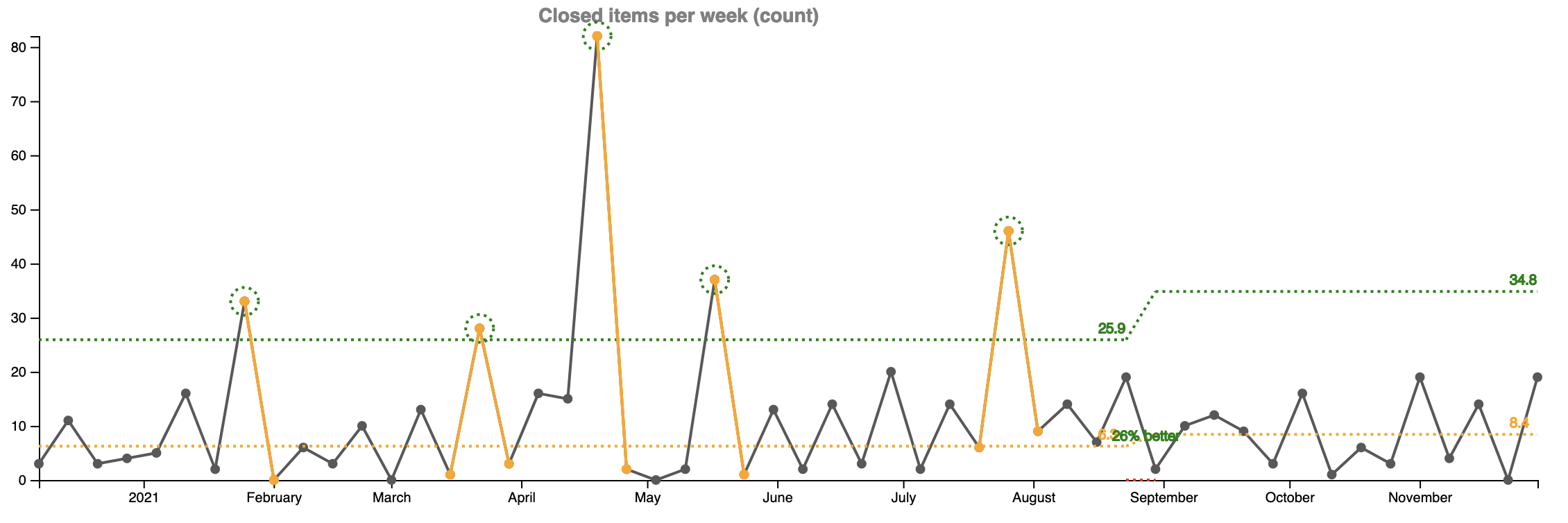
To my surprise we actually did better. 26% better! Since the end of August, we’re releasing 8.4 stories per week, whereas before they were 6.3. How did that happen?
I have a theory that prior to the change in August, we were pulling random developers to investigate customer reported issues. Depending on the severity this would mean that sometimes a developer would stop working on a new feature, investigate the issue, do a hot fix and the go back to continue working on the new feature. Switching context this way wastes so much mental capacity and leads to delays. If you want to read more about how bad it is check out the book Deep Work by Cal Newport.
How about how much time it takes us to release a new feature (the team's cycle time)? It's 50% better. Before it used to take this team 28 days to release a new functionality, now it takes them 14. Again my suspicion is that this improvement is due to the more focused work and less context switching.
In summary, I want to leave you with two thoughts. The fist one: try, experiment, see what will happen, take action. Collect data before and after your experiment. Analyze and extract meaning from data. The experiment did not work? Revert back and try something else. The second one: have more that one metric to look at. Software development is very complex and multifaceted. You need a holistic view.