Seven Habits To Create Reliable Software - Don’t Assume Anything
This is the fourth part of a collection of seven blog posts about how to write reliable software. When a new developer joins the company we go over this list, and so I’ve decided to organize my thoughts on the subject a bit and share them with a wider audience.
Face it: you’re trying to write reliable software on inherently unreliable platform. The network suddenly may become incredibly slow, there may be database locks from too many concurrent operations, external service that you rely on may be down. You’re not born with a silver spoon in your mouth. Shit happens all the time.
All the developers at Komfo are notified about all exceptions that happen in production. A while ago we started receiving an error that we haven’t seen up until that point:
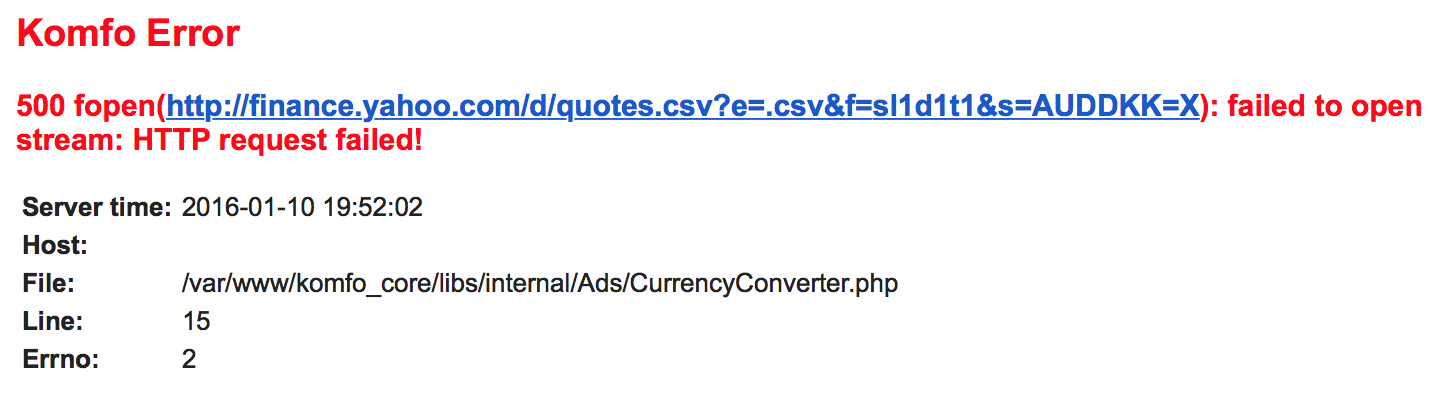
The cause is pretty straight forwards: we try to make an HTTP request to finance.yahoo.com to check the FX rate for a number of currencies agains DKK, and somehow the request fails. This is the error that we get when such a request fails. The code that is responsible to get the FX rate looks like this:
public function getRate($from, $to) {
$url = 'http://finance.yahoo.com/d/quotes.csv?e=.csv&f=sl1d1t1&s=' . $from . $to . '=X';
if($handle = fopen($url, 'r')) {
$result = fgets($handle, 4096);
fclose($handle);
}
$data = explode(',',$result);
return $data[1];
}
Ignore the fact that getting the FX rate by downloading CSV file, reading the first 4096 bytes, and parsing it in 2016 is sub optimal. I want to focus on something else. The person who wrote this code didn’t take any precaution as to what might happen should the fopen() call fails. It just throws a PHP error. Big deal, right?
As you know the Internet does not guarantee a delivery. The network stack will notify us in case of an error, but it is up to us how to handle it. Most of the time, such errors are fixed with a simple retry logic. This is what we did and currently do not see any more errors:
public function getRate($from, $to) {
$url = 'http://finance.yahoo.com/d/quotes.csv?e=.csv&f=sl1d1t1&s='. $from . $to .'=X';
$maxTries = 5;
do {
$handle = @fopen($url, "r");
sleep(1);
}
while($handle === false && --$maxTries);
if($handle !== false) {
$result = fgets($handle, 4096);
fclose($handle);
}
else {
throw new Exception('Can not get FX rate from Yahoo: ' . $url . ' message: ' . error_get_last()['message']);
}
$data = explode(',',$result);
return $data[1];
}
In case of a problem, retry maximum of 5 times, sleep 1 second. Fail only if there is no result after the fifth try. You can adjust the sleep interval to suit your needs. You can also increase the interval after every retry - e.g. first wait for 1 second, then 2, then 3, then 5, 8 and so on. Thus you help the external system by not DoS-ing it and leaving it a room to recover.
On the fifth try, if we still don’t have any luck, an exception is thrown with the error details. The @ before fopen() suppresses the error immediately, but we are extracting it later with error_get_last(). Such are the joys of programming in PHP.
One thing that can be improved is to check the return HTTP code. If the code is 403 (forbidden), there is obviously no need to retry. In our case it’s not applicable, but it may be so in other situations.
The practice to retry async operation a limited number times before finally giving up is pretty common. It is also very useful when fixing flaky high level automation tests. Various libraries are created, currently for our Ruby tests we use the anticipate gem:
sleeping(1).seconds.between_tries.failing_after(3).tries do
some_method(args)
end
If an exception is throw in the block, it will retry the specified number of times.
Besides the results from async operations, don’t make any assumptions about the following cases (non-extensive list):
- If an exception is thrown, who will catch it?
- Does the order of a list is the same you assumed it would be?
- Are all the keys you need in the hash you process?
- Do you check for the proper variable type (when working with loosely typed languages)?
- What will happen if the network is slow? Or slow?
- What will happen if instead of text, you receive a binary data?
With so much to consider, you might start thinking that you need to add a lot of extra code, that is of no significant benefit. As everything in life, you need to balance between both worlds - too much defensive programming and no extra checks. If it helps, here is one of the most costly bugs I’ve seen. We were handling an input from external system. Suddenly that system changed the format of the JSON response send to us. An extra field was added. Instead of ignoring this field, (we relied on the fields to be in particular order) the program started using this new filed in finance calculations immediately. As a result of miscalculations, in a matter of 2 hours we lost $50,000.
At last, there is an excellent book on the subject by Michael Nygard - “Release It!”

In the book the author describes four interconnected practices for resilient software. In short they are:
Bulkheads: When an error in one part of your system occurs, it should not take the whole system down. The problem should be contained. This is a direct analogy to how modern ships and submarines are built. Bulkheads construction allows vessels to stay afloat even in case of extensive damage.
Timeouts: if a resource is busy or unavailable, try again later (the example from above)
Circuit Breakers: Just like in your home, if you try to drain too much power, the circuit breaker shuts down the current to prevent further damage. In case some part of your system is overloaded, it should start rejecting requests until it recovers. If the other components in your system use timeouts (the previous practice), you should be able to recover easily.
Handshaking: A way to tell the client that you’re currently too busy, and you will queue the new request and process it later. Nowadays message queues are considered a standard part of any decent software system so just use off the self solution instead of rolling your own.
The rest of the related posts can be found here: