Seven Habits To Create Reliable Software - Monitor Production
This is the fifth part of a collection of seven blog posts about how to write reliable software. When a new developer joins the company we go over this list, and so I’ve decided to organize my thoughts on the subject a bit and share them with a wider audience.
Definition of Done pic.twitter.com/2kEKhHHstY
— Andrzej Krzywda (@andrzejkrzywda) January 25, 2016
Releasing a feature to your customers is not the end. It’s just the beginning. Remember the quote “You Build It, You Run It”? In order to “run it” you need proper insights into what happens once your customers start using your shiny new feature.
There are three main types of monitoring metrics that you need to pay attention to.
System Health
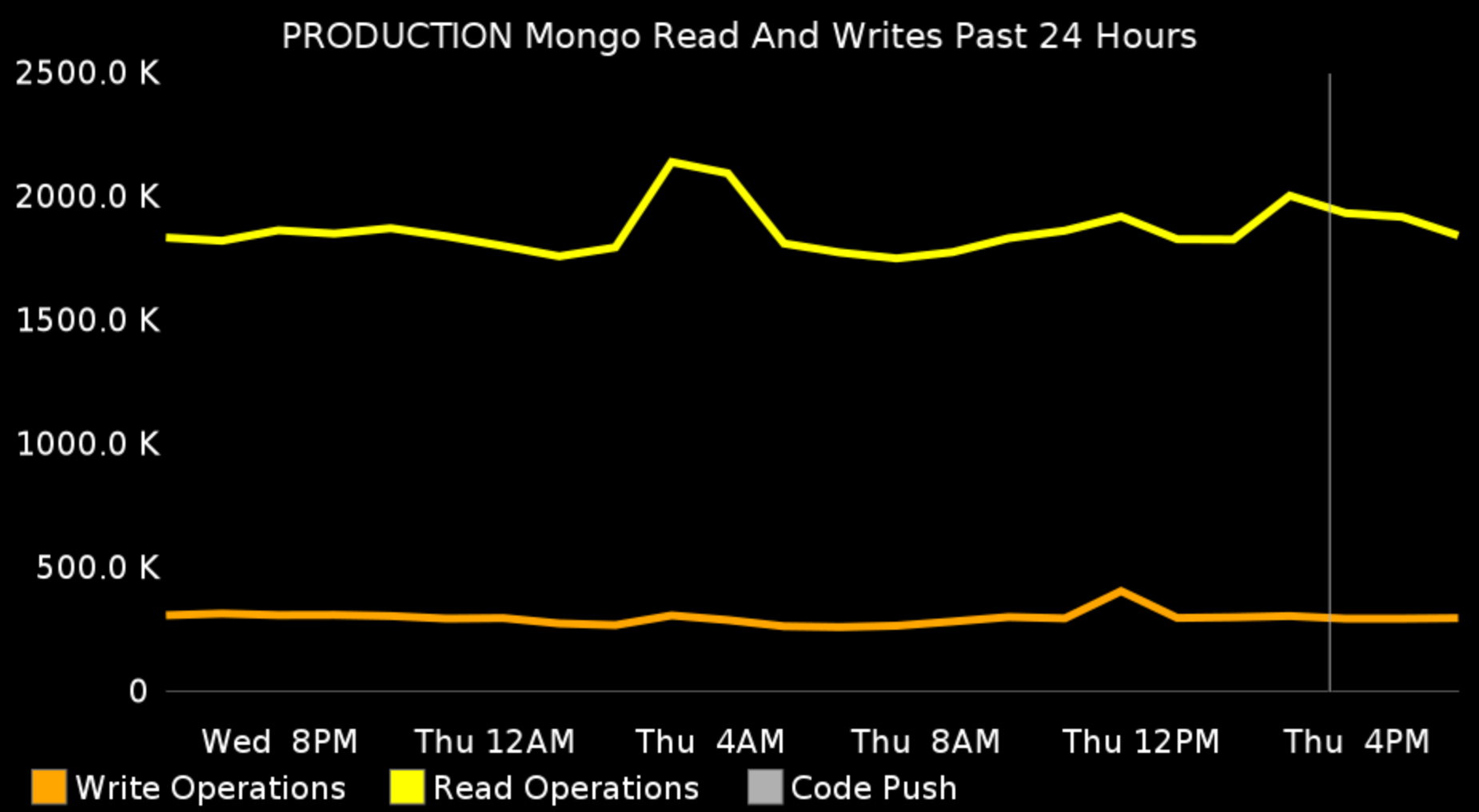
These are the usual suspects such as CPU and memory usage, disk space, the number of external API calls, database operations etc.
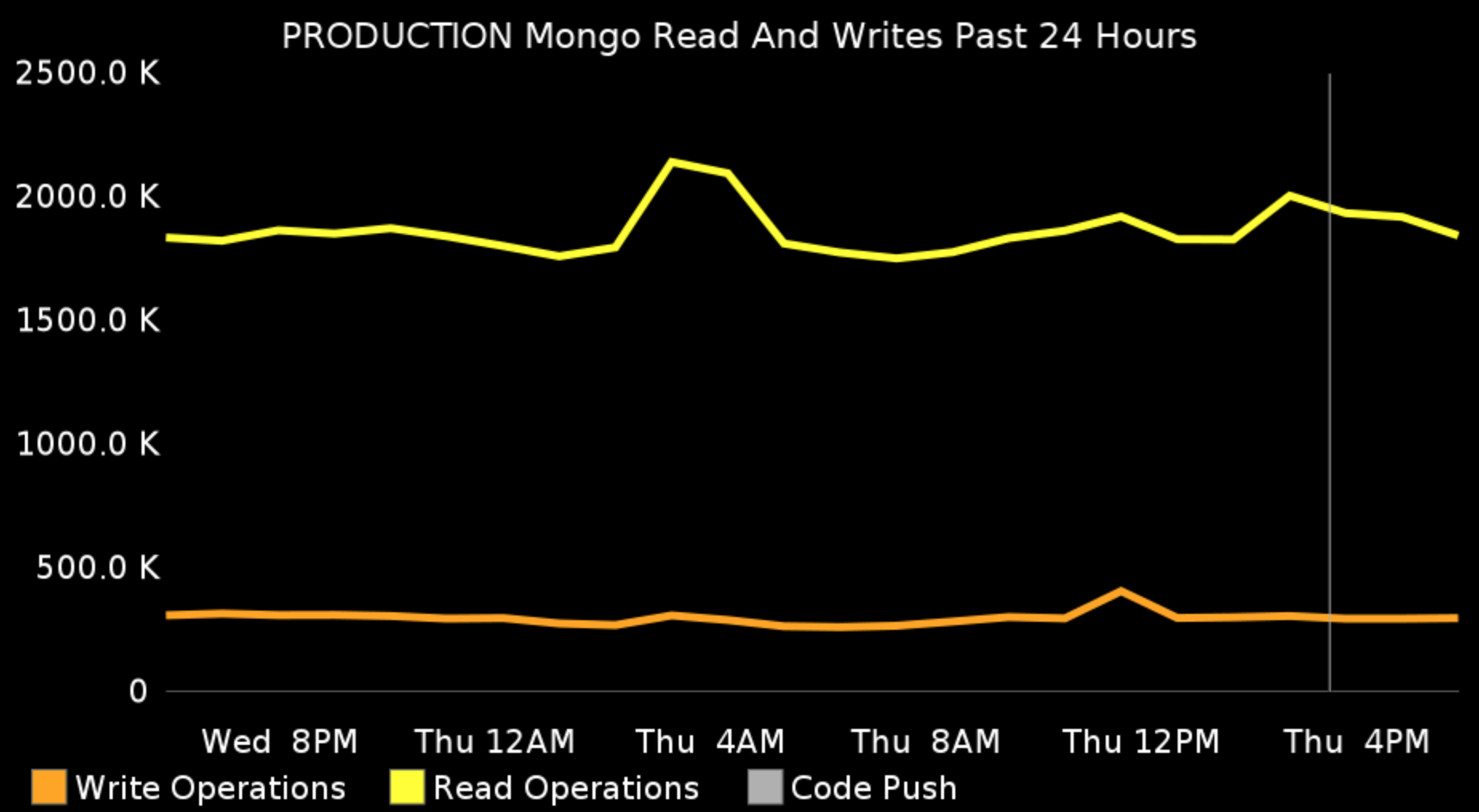
The system metrics are the first thing that your operations team is monitoring. However you, the developer, still need to have access to them and you still need to receive any notifications, about thresholds reached. Most of the times your ops team does not know why a particular statistic is going down, or up. They lack the context and only you have it, because you wrote the feature.
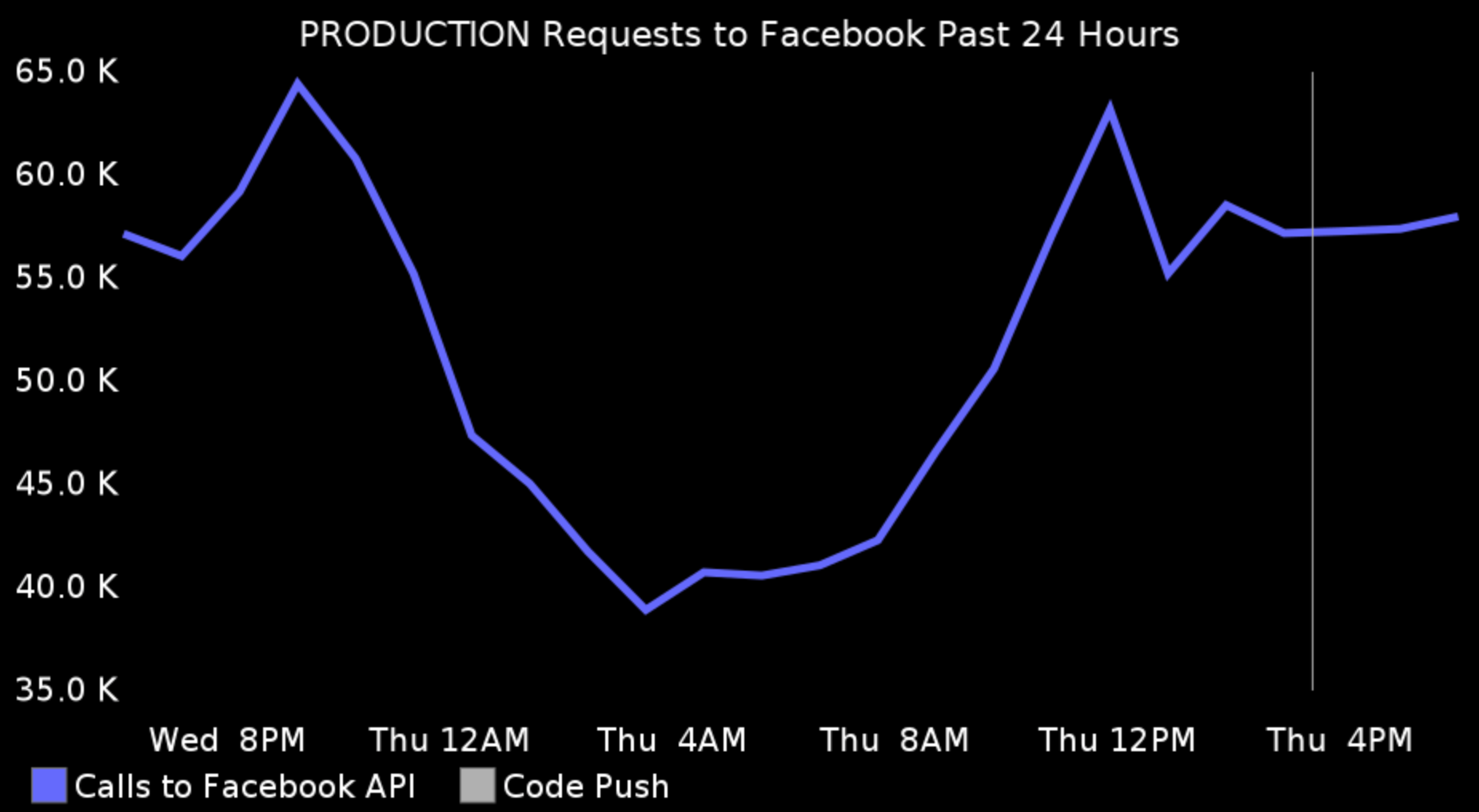
So, if you’re not doing this already, start receiving system notifications today. This will save both you and the ops team a great deal of wasted time. On the other hand, I’ve worked at companies that were not allowing the developers to look at these metrics, citing regulatory PCI compliance. This is utter bullshit as nowhere in the standard does is say that developers should not be able to look at these graphs. What developers should not have access is customer data and personal identifiable information. But you don’t need those in order to monitor production. You just need the aggregate data.
Errors and Exceptions
This is a little bit tricky, as sometimes the developers are catching exceptions and suppressing error messages (which is so wrong). You need to be notified about all abnormal code execution in production.
Errors in production need to be fixed with highest priority. Even faster than the bugs found in the current feature under development. Why? Because the customer found this issue! Because the customer is actually using your service and out of his pocket comes your salary. If you do not want to disturb the current iteration schedule, then you need to have a dedicated person or a team looking at the errors and fixing them constantly. More on the problem bug fixing in the next blog post.
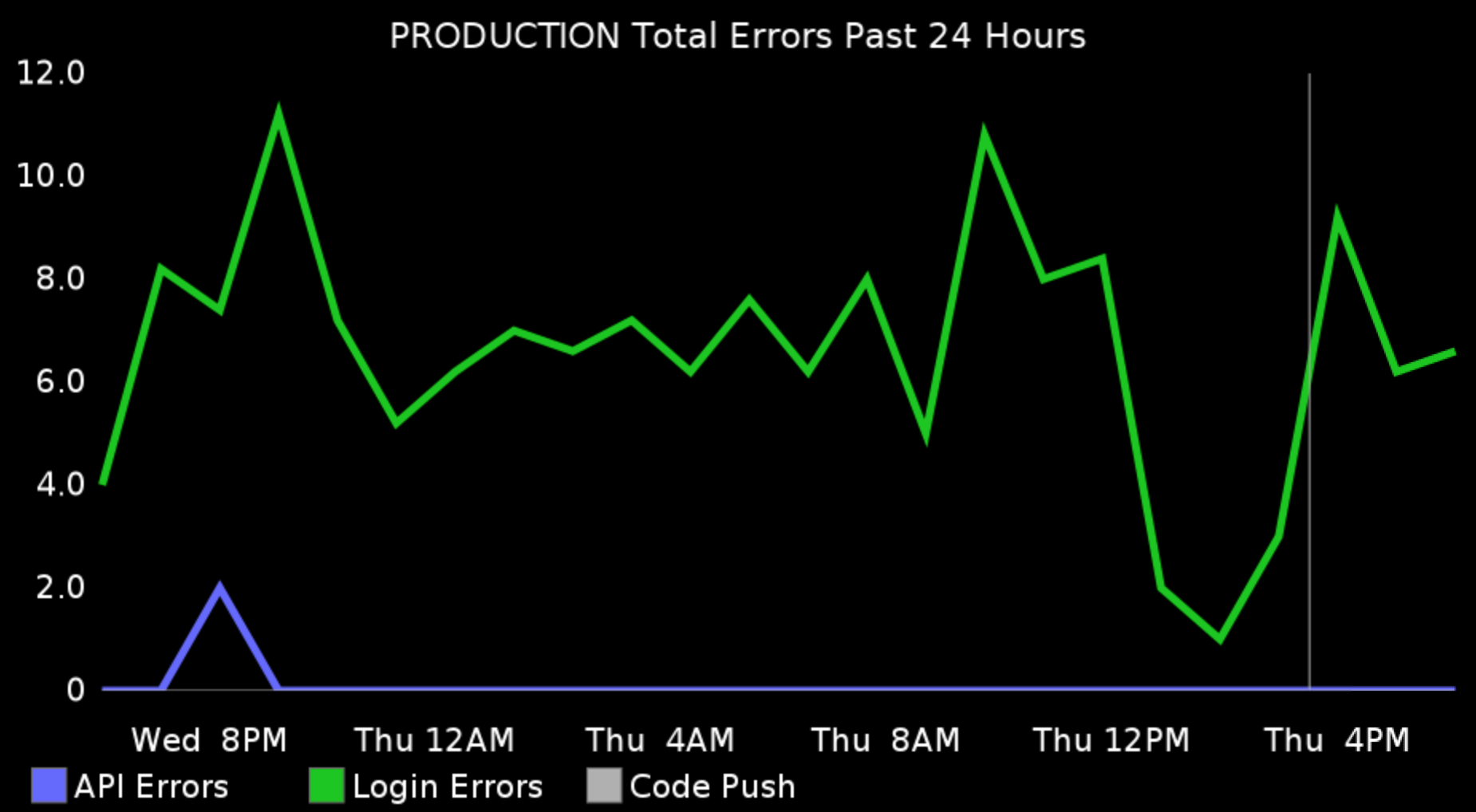
Business Metrics
These depend on what kind of service you provide - e.g. if you’re a streaming service provider (Netflix, Amazon) maybe track how many movies are being watched. If you’re an e-shop then track the number of orders per day.

Businesses are diverse, but they have one goal in common — they all need to make money (otherwise they are call non-profit organizations). Make sure you track and monitor the revenue. This maybe too sensitive in some companies depending on structure, politics, etc. Be careful, your mileage may vary.
Notice that on some of the graphs above there is a thin vertical line. This line represents the time when we pushed a release to production. In the screenshots above, it’s only one release for that day, but some days, there are more than 20 releases. Why is this correlation is important? You want to know if after a certain release, the disk writes went 50% up, or the external requests are 70% down. Then you can easily revert the change or if you’re following the first habit — to work in small increments — you will find the culprit immediately.
The methods above work for a backend application when you can peek inside the processes. Your frontend however is being executed on the client browser and by default you don’t have any visibility there. So far, the best solution I’ve seen to solve this problem is track.js.
How about if you’re not working on a SaaS product, but on one that is installed on customers premises. Usually you don’t have realtime monitoring data. That is true, but it’s also true that you can architecture your product to periodically ‘phone home’ and send usage data. If this is not possible then it may send data only when a problem happens — crash, exception, error. Customers usually do not object to this practice because they like more than anyone else for the problem to be fixes. Most of the desktop OSes are doing this now anyway?
The same is true for the current mobile OSes:

There are a number of ways to consume the information from production, have a TV in your room, receive emails, receive text message or notifications in the group chat. There is no univeral rule, pick the solution(s) that the team agrees on are the best. Next week we’re going to talk about that to do with those notifications.
The bottom line is: The same way the pilots are not flying blind, you want to have as much insights as possible as to what happens with your application when your customers are using it.
The rest of the related posts can be found here: