Seven Habits To Create Reliable Software - Solve Problems Immediately

This is the sixth part of a collection of seven blog posts about how to write reliable software. When a new developer joins the company we go over this list, and so I’ve decided to organize my thoughts on the subject a bit and share them with a wider audience.
In his book, The High Velocity Edge, Dr. Steven Spear describes four key capabilities that differentiate the best companies from the rest:

- Problems are made visible as soon as they occur
- Solve problems immediately
- Spread the knowledge gained
- Constantly improve and repeat
This blog post is about the second capability (the previous blog post is related to the first capability).
A CI Story
Imagine you’re a developer, working within a small team. You have a continuous integration (CI) server up and running. All your automated tests are executed after every code push.
One of your colleagues, lets call him John, needs to head home early. He commits his last change for the day and without waiting for the CI job to complete rushes out of the building. The CI job takes 10 minutes to complete (although the aim should be jobs to run all tests for less than 5 minutes). At the end the job fails. Your build is broken. Now every developer on the team is blocked until the build is fixed again. Had your colleague waited until the end of the job, he would have seen the result and (assuming he works in small batches) would have easily fixed the problem. Now this is the team's responsibility.
For the sake of the argument, let’s say that no one bothers to do the fix. You might say -
“John is the only one that touches this functionality. He’ll fix the build in the morning”.
If you want to commit a new piece of code at this moment, the build would still fail. Your code might be OK, but the build would fail because of John’s commit. Your commit might also be problematic but the previous build failure is masking it. You have no way of knowing if your new code will pass the tests or not.
Usually the CI jobs that run after every commit include a number of stages with different checks. The stages are arranged from the fastest tests to the slowest - e.g. linter, static code analysis, compiler, unit tests, api tests. If the linter test fails the next checks will not be executed. Hence, any problems with the unit tests will not be discovered until the linter checks are fixed.
As a rule of thumb you should push new code only when the last build status is green. Do not push when the build is broken (unless you’re pushing code to fix the build). Wait for the result of your last commit before going away from the computer.
This is why it’s so important to keep the build green and to fix any CI failure immediately. It’s not only so that you can feel confident in your new piece of code but for your whole team to be more productive. Otherwise you may be subjected to the parking lot therapy.
Fix It While It’s Hot.
When an issue occurs you should swarm, find the cause and fix as soon as you can. The lead is still hot and the traces are there. Everyone's memories are still fresh. This is the best moment to do it. If you’ve followed the first habit - to work in small batches, most of the times it’s easy to spot the culprit. Prioritize fixing problems found by your customers over delivering new features. Have a dedicated team to handle the extra fixes if you do not want to disrupt your core team.
Minor Problems
Minor problems are the easiest to ignore. If you don’t fix the problem and ignore it will raise its ugly head later and will still irritate you.

Different small problems will keep piling up one after another and in some case, the variation caused by them can cause the whole system to go down. Most of the times this is how complex systems fail. It takes a number of seemingly small problems. Complex systems will not fail because of only one event. There are multiple notifications or warning signs before the system crashes completely. Two of the recent examples that come to my mind are the Space Shuttle Columbia Disaster and Air France Flight 447.
Minor problems are what Todd Conklin calls ‘weak signals’. Weak signals are your early indicators. They are telling you something, listen to them.
Monitor Fatigue
When you constantly receive notifications about problems you become desensitized to them. You start ignoring them and accept them as normal. Most of them may deserve to be ignored. However at times, a notification for important problem will arrive, and it’s very likely that it will get lost in the number of text messages or emails you receive. That’s why you should strive to fix problems so that you receive less notifications. If you do not intend to fix a problem, then have it so that you do not receive notification about it. Separate the wheat from the chaff.
Normal Variation
Bear in mind that not all problems are equal. Dr. Deming taught us that in every process there are standard variations due to the inputs, environment or a bunch of other factors such as life. So rushing to fix all the errors might not be applicable (because you may not be able to reproduce the right conditions) or practical (because the problem might be minor and it takes lots of resources to debug and fix it). You need to establish upper and lower control limits.
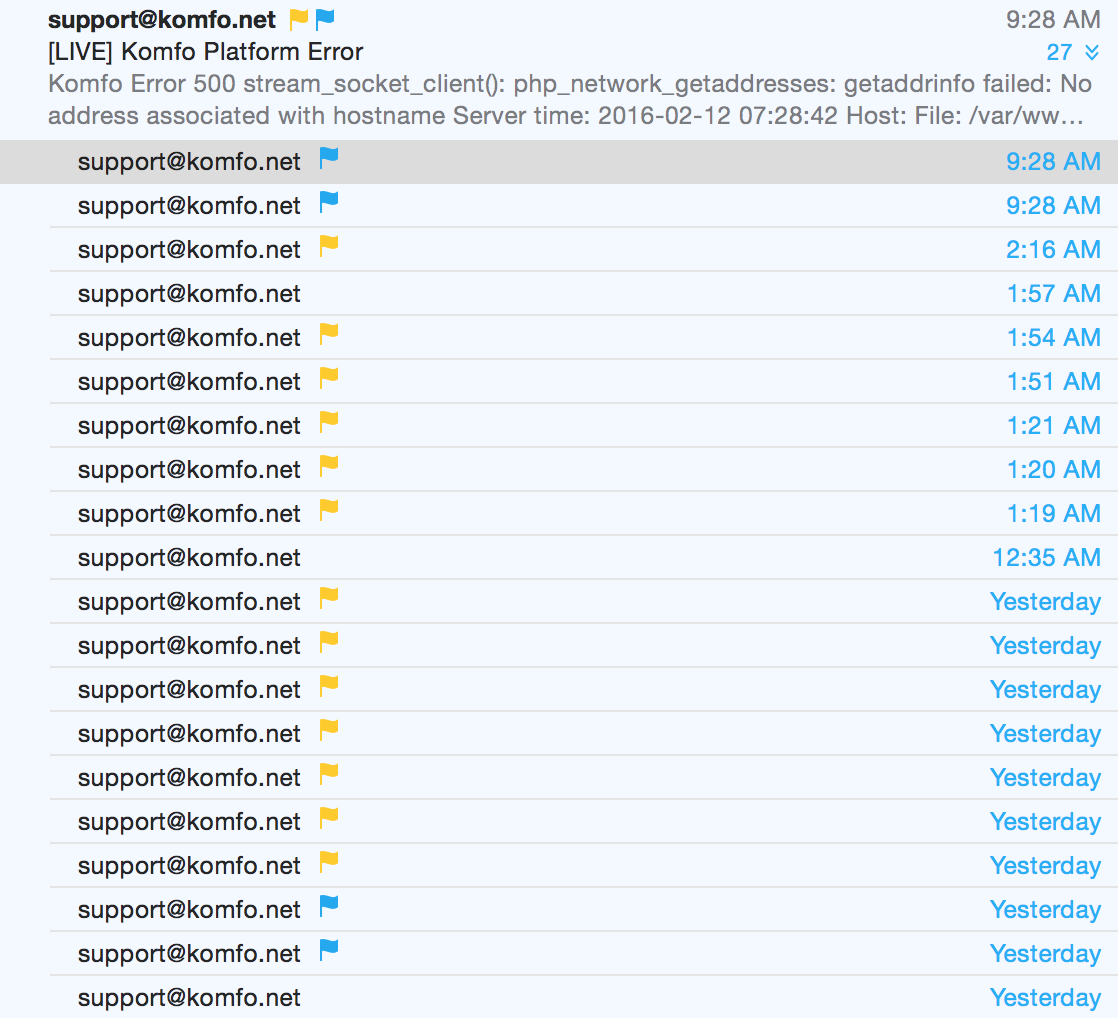
For example I receive emails about all exceptions and errors in production. I don’t react on the first occurrence of any of them. I usually color code the different errors, group them together. When I receive more than what my internal control limit is (let's say more than 3 of the same errors in less than 24 hours), I start working on the problem. This also has the added benefit that you have wider sample size so it’s easy to find causation in that larger pool.
The rest of the related posts can be found here: