A Tale of Two Bugs
(or why you should optimize for low MTTR)
All bugs are not created equal. Ideally, we want to catch them all before releasing software to our customers, but this is a pipe dream.
In Toyota Kata, Mike Rother explains the improvement kata, which in essence is an ideal goal (true North) that we make small, incremental steps to achieve. We can get exponentially close to it but will never achieve it.
So why there is no bug free software? Because we’re (imperfect) humans, we make mistakes. Because our software is complex. Because it operates in less than ideal conditions. Because, unlike machines and buildings, a single, unexpected character can cause catastrophic consequences. Because the price of building high reliable software is too high for most of our purposes. And because what we, as developers think as a feature, may be considered as a bug by our customers.
Every piece of software has defects, no matter how perfect it looks. They are just not found yet. And for the life of this software, they may never be found. In this case, can we consider them as defects? If a tree falls in a forest and no-one is around to hear the sound, how do we know that it really made a sound?
That why it’s really important to investigate and learn from the bugs that are reported by our customers. We may never find the other ones anyway.
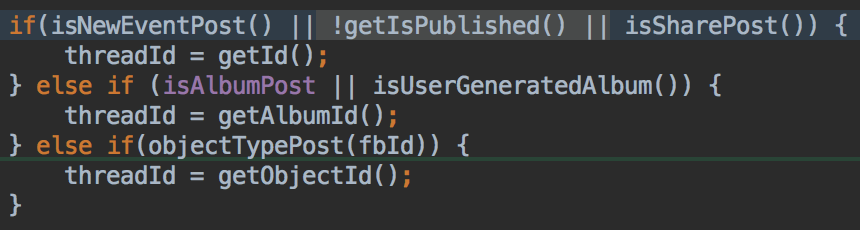
Let me show you two types of bugs that escaped undetected and were reported by our customers. Both are very recent, in a backend Java code. First, the preventable one:

The problem was that the first argument when initializing BasicDBObject is ‘fields’, which is a property of the object. When this method executes, this property is null, so a null pointer exception occurs. Instead, the first argument when initializing BasicDBObject should be ‘field’ (singular), which is the first argument in incrementField method. Although this is clearly a typo, the code is perfectly valid and neither the IDE, nor the compiler complains.

And here is the problem, if this code was executed at least once — by unit, API, or manual test, it immediately would have thrown an exception, and the developer would have noticed. I’ve already written about the importance of writing any type of automated test for the code we’ve just developed (or are about to develop in the case of TDD). This is standard developer work.
The first bug was completely preventable in-house, and it’s very bad that our customers found it.
This is the second bug, the undetectable one:
I’ll spare you the domain specific details. The gist of it is that we should update a specific type of object with additional information. The problem is that no matter how many times we execute this code, we will not catch this bug.
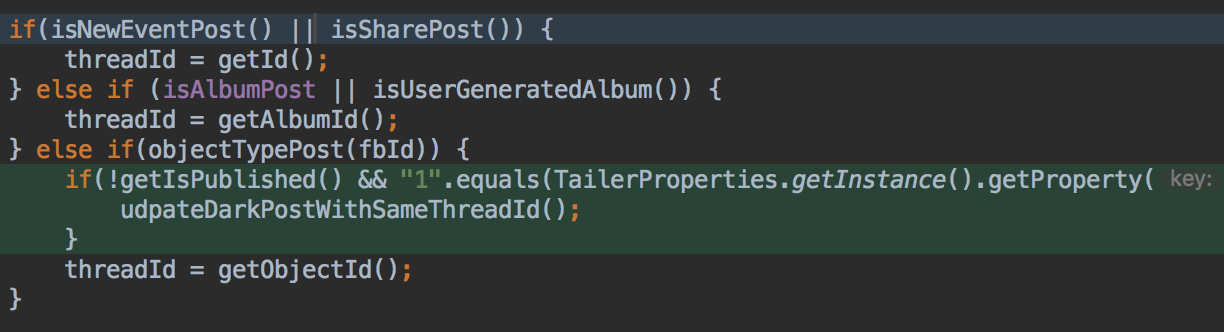
This bug is due either because of missing functionality, incomplete specification, or just customers using the software in an unintended way. Whatever the cause is, the customers do not care and required an out-of-scheduled-releases fix.
So here is the philosophical difference between those two bugs: the first was easily prevented by a simple preventive techniques. The second one, realistically, could only be caught by the real customers. These are the two basic types of bugs in all the software.
So you may wonder, what is the ratio of those two bugs? If the second type is negligible percentage from all the customer reported bugs, why care? First let me say that, there is no exact science that can measure precisely the second type of bug. It can pretty easy become a political mess with lots of blame thrown around. Blame the product owners for missing data in the specification, the developers for failing to know inside out your complex system, or the QA for not catching the bug in the ‘testing phase’, for not acting like a ‘real customer’. However, if you care to learn and not to blame, by applying common sense, you can easily identify the second type of bugs.
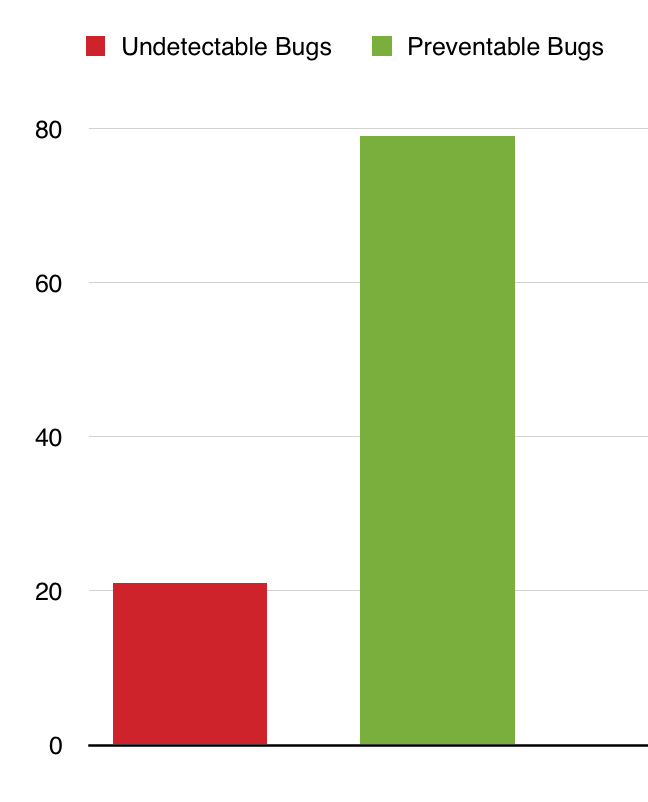
At Komfo, we investigate every bug that is reported by our customers in order to constantly improve our system better. We found out that 21% of the bugs are ‘undetectable’ (this number is suspiciously close to the 80/20 Pareto principle).
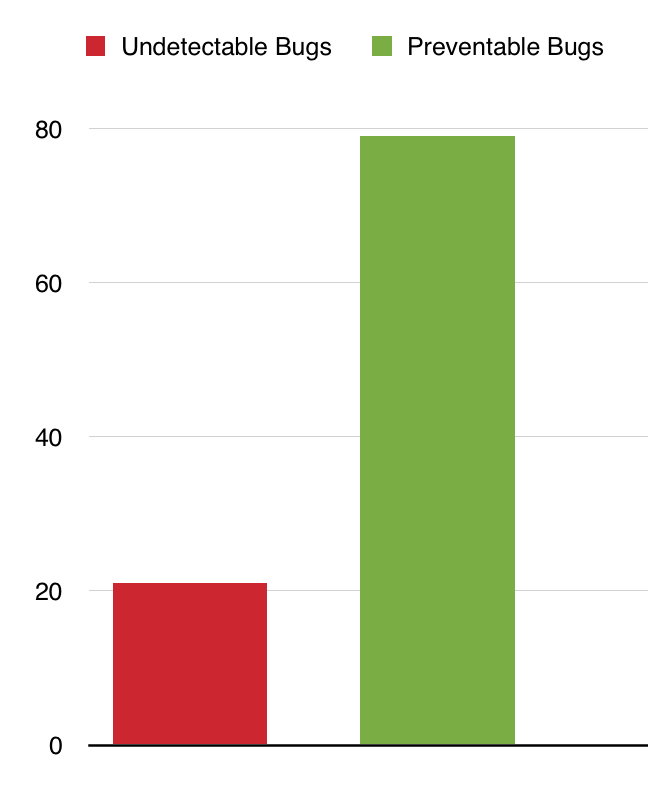
Those 21% may actually be preventable, but it does not make an economic sense to release 100% bug free software. The tricky part is to find the balance between how much it costs you to detect bugs in the pre-release phase vs what the cost of the bugs that are detected by your customers is.
The preventable ones (79%) can easily be caught if we do the right things in the pre-release phase. People are now calling it Shift Left (at BGPHP15 I gave a PHP tools specific presentation about this topic).
But there is nothing we can do to detect the second type of bugs in the pre-production phase. They will always be there and we should always expect them. As Todd Conklin always says, there will always be incidents, we can’t present them, but we can learn from them, detect early and limit their consequences (by the way, you should subscribe to his podcast, it’s really good). Things like proper exception handling, periodic health checks and repair, even periodic restarts (e.g. US Navy had a procedure to restart Windows NT system in a weapon control system every 24 hours to combat memory leaks).
A common misconception (if уоu believe that all defects are preventable) is to measure only MTBF (Mean Time Between Failures). Which is exactly this — at what period a bug will occur? We will never eliminate 100% of all the bugs, so there is no point trying to increase MTBF. Instead we should measure MTTR (Mean Time To Recover), or how fast, once a bug is reported, we can identify the root cause and fix it.
MTTR > MTBF, for most types of F: http://bit.ly/9teuCF
— John Allspaw (@allspaw) November 7, 2010
One way to achieve lower MTTR is to ‘Shift Right’ and do proactive monitoring on your live environment for exceptions. Check them every day and fix all unexpected errors with highest priority. By the time your customers report and error, there is a good change that you would have noticed and fixed it already. Your customers will be delighted that you’re on top of things and all they need to do is to restart their browser or download the new version of your app.
Another way to achiever lower MTTR is if your code is structure properly, the developers can easily debug locally, with production data, and once the fix is ready you have fast automated tests to make sure you have not broken anything. Regarding MTTR at Komfo, 60% of the bugs reported by customers are fixed in the same working day.
If you liked this blog post and want to learn more about how to accelerate your software development by analyzing the reported defects, join me at CraftConf 2017. I’ll be giving a talk about the patterns that have emerged (and how we’re applying them in practice) when analyzing almost 3 years worth of defects.