On Test Environments
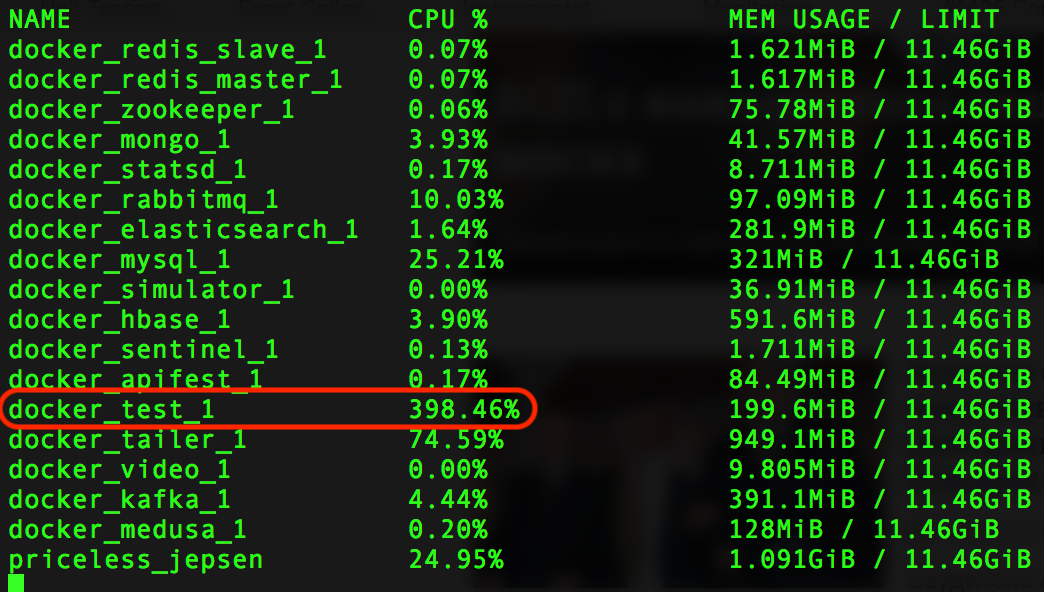
One of my biggest problems in software testing has always been the test environment. And more specifically the problem that I had little control over it. I could not deploy whenever I liked, neither could I upgrade it, or I was not allowed to have access the internals. I had to ask someone else (most likely a system administrator) to change/update the environment, or to extract data from it.
In my early days the test environment had to be upgraded by hand — it was installed on real hardware after all. A single upgrade would usually take days.
Then came the virtual machines. You still had to do stuff by hand, but now at least the host os would enable some level of automation. At one of the companies I worked, we had a nightly build that would compile all the code changes from the previous day to into a binary file. I created a script to take this binary file and to build a virtual machine image with it and setup the software under test with a basic configuration. When people came to work in the morning they could just download the new image and start testing on the latest build. This saved us hours as before everyone was performing the same overlapping operations on their own test environment.
Then came the containers and they streamlined the process of creating and configuring test environments even further. A single container runs a single process and it would boot very fast compared to a virtual machine.
Nowadays it is really important to be able to run high level automated tests after every commit. If a test breaks you’ll know exactly which commit was the culprit. For this reason running tests on predefined period (e.g. every night, every 4 hours) is suboptimal as the run will include changes from more than one commit which further complicates finding the cause of a failure.
Having fast, dedicated, created on demand test environment makes the above and even more possible. It is the gift that keeps on giving, and those are the reasons:
- Have an app setup the same way as in production
- Fast start and tear down
- Test in isolated from the internet environment (i.e. hermetic environment)
- Being able to run high level tests in seconds on a laptop
- Being able to trace, play and pause a single test across different services
- Even if all tests pass, to continue to probe for unexpected/unseen problems and anomalies
- Have the test environment described as a code
- Exclude the environment as a cause when investigating a flaky test (because it's used for automated test only, can be reproduced with code the same way every time and its state and data are reset every time the tests start)
During the past few years I spoke at conferences about fast tests, deep oracles or super stable tests. None of those advancements could be possible if we don’t have fast to boot, dedicated test environment that we have full control over. Such an environment can be created with regular servers (although is going to be slower), but currently the best way is to use containers. Maybe in the future, unikernels will be the norm. I’ll try to keep my recommendations technology agnostic as much as possible. I’ll also be writing from the perspective of high level tests.
The high level plan for creation of such environment is:
- Clear any previous state and data
- Download the latest artifacts to be tested
- Start the containers and do app specific setup
- Setup the service virtualization anything outside of your control
- Run the tests
- Collect and analyze the generated data
- On the next commit go to step 1.
Those points are discussed bellow.
Start with one Service
Even if you have fully containerized setup of you app, start your test environment with a single container. This will be the walking skeleton test environment app. It’s one service only but in order for it to run you’ll need more than the service itself. There will be databases that need to be attached, API authentication service of some sort. You’ll need to figure out the mechanism to download the latest binary artifacts on each commit and to configure them. Run a few tests to “smoke test” (pun intended) the environment and once this is ready proceed to add more services to you test environment setup. Also it’s going to be easier to debug infrastructure problems with one container instead of seventeen.
Reset
Before the tests start, you need to reset any leftovers from the previous run. They may include artifacts, data, logs, configurations. This is needed for two main reasons — to start each test run on a clean slate with exactly the same conditions each time and also to be able to extract meaningful information from the system after the run completes and correlate it to specific code revision. At minimum you should restart the containers (or the OS). The next thing is to remove any old source code and logs.
Depending on how your app is structured, deleting the log files may not be an option. In this case the best thing you can do is to keep the log file, but truncate its size to zero.
sudo truncate -s 0 docker inspect -f '{{.LogPath}}' docker_nagual
For databases reset, check the section bellow.
Start Order
If your app contains multiple services their starting order can be important. For example one service may check upon start if it has a connection to Redis cluster and shutdown if such a connection cannot be established.
If you’re using Docker, docker-compose has a mechanism to explicitly order the way the containers start. This is accomplished with depends_on keyword. However this solution is not bulletproof. Docker considers a container to be started when the boot process concludes. The container may be up, but it may take additional seconds for the main process to actually start, to open a network port, or to respond to a query. In such cases you need to take additional measures to ensure that the starting of containers does not continue unless the process is really in a running state.
One inelegant, but effective way is to not start the process in the current container unless a port in another container is not already open. One simple way to do that is by running netcat in endless loop that breaks only when a three way handshake connection concludes successfully. Here is an example:
while ! nc -z zookeeper 2181; do sleep 1; done && while ! nc -z kafka 9092; do sleep 1; done && start_my_app.sh
In the example above first for the port of Zookeeper needs to be open, then the Kafka port needs to be open and just then the main app starts. Both Zookeeper and Kafka and running in separate containers and it takes a while for them to start to start. Our app requires them both to already be running, otherwise it shuts down.
Custom Setup
Some services will also require additional custom setup. Besides databases, others might be:
- Loading of custom settings for central configuration services such as Zookeeper or ETCD
- Setting up elastic search mappings
- Adding entries to
/etc/hostsfiles to redirect traffic for 3rd party API service virtualization - Seeding a service with synthetic data.
Setup Databases
In order to start from а clean slate each time, besides restarting the servers/containers, replacing the code with the newest revision and removing the old logs, you also need to have fresh and empty databases.
One of the principles that define good automated test is that the test should create all the data that it needs, in a prelude, and then continue with the actual requests to the app. This enables the tests to be run on empty database also to be run safely in parallel and in random order.
Even with empty database, you still need the latest DB schema before the tests start. All the tables should be there, with the proper type of columns (also triggers and indexes if any). Depending on how the backend is written maybe some specific indexes need to be installed in a NoSQL DB.
The point is that you need the latest schema applied. There are two ways to do that. The best one is to be able to recreate the schema from a script. It assumes that every time, even for the smallest schema change, this script need to be updated. It’s a really good practice as this DB creation script is under version control, can be reviewed, its history tracked etc. Unfortunately, in the companies I’ve worked so far, even if such script exists, it was not kept up to date. In this case the other option is to dump the existing DB schema from a running server and apply it to the testing environment.
mysqldump --defaults-extra-file=config.cnf --single-transaction --skip-triggers --no-data $core_db | sed 's/ AUTO_INCREMENT=[0-9]*\b//' > schema/schema.sql
The sed command at the end just removed the auto increment, and it’s optional.
Before the start of the tests, you can dump the latest schema (w/o the data) directly from a stage or production environment and then you restore it on an empty DB instance. This approach has two distinct disadvantages: the first one is that it may be a bit slow, depending on the size and the complexity of the schema. The second one is that you actually need to have the credentials to dump the DB schema (which may be problematic for security reasons) also you need a network to do this. It actually defeats the goal of having self sufficient, hermetic test environment that you can setup without internet.
Depending on the design of your app, you may actually need data in some of the SQL tables or in the NoSQL collections. These are so called configuration tables: currency and country codes, language constants, mapping coordinates etc. In this case you need to specifically dump the tables along with their data.
If you subscribe to principle that each test creates the data that it needs, you’ll need one more piece of data. You’ll need at least one user in the system to authenticate against, to get the whole ball rolling. I call this user the God user, as it is the first in the empty test environment universe. It’s OK to create this user with a single DB command as it usually affects only a few rows.
mysql apps -e "INSERT INTO users (id, first_name, last_name, email, phone, active, invited, invite_hash, api_token, api_token_expires, last_login) \ VALUES (1, 'Emanuil','Slavov','some@mail.com','9998565432', 1, 0, 'fake_invite_hash', '34ad6a230b95f3a6d18076cbb7c756d7323f3ca6', '2013-10-30 13:05:15', '2017-01-24 12:31:14’)"
The data that is created in the database is synthetic and it has very little value after the tests pass. In order to speed up test execution we actually run the database not form the filesystem but entirely from memory. For MySQL, the simplest way to do this is to append an option to the command line that starts the server:
mysqld some_options --datadir /dev/shm
Running a database from memory only also speeds up the time to delete this data. As it is stored only in memory, when the container is restarted the data evaporates. There are more details in this presentation or watch the short version video.
Stub External Dependencies
A modern application most likely will have some sort of 3rd party integration (social networks, payment providers, storage etc). In order to have fully hermetic test environment, they should not require internet connection while running. As mentioned above, you may be required to have an internet connection during the setup phase - for example do download a repository from GitHub or to dump a DB schema from running instance. Generally however, its always a good idea to stub/mock/fake any external API requests that are not under your control. This also includes resources internal to your organization that are not easy to get to run as part of your hermetic test environment: e.g. a mainframe server or Google Big Query instance.
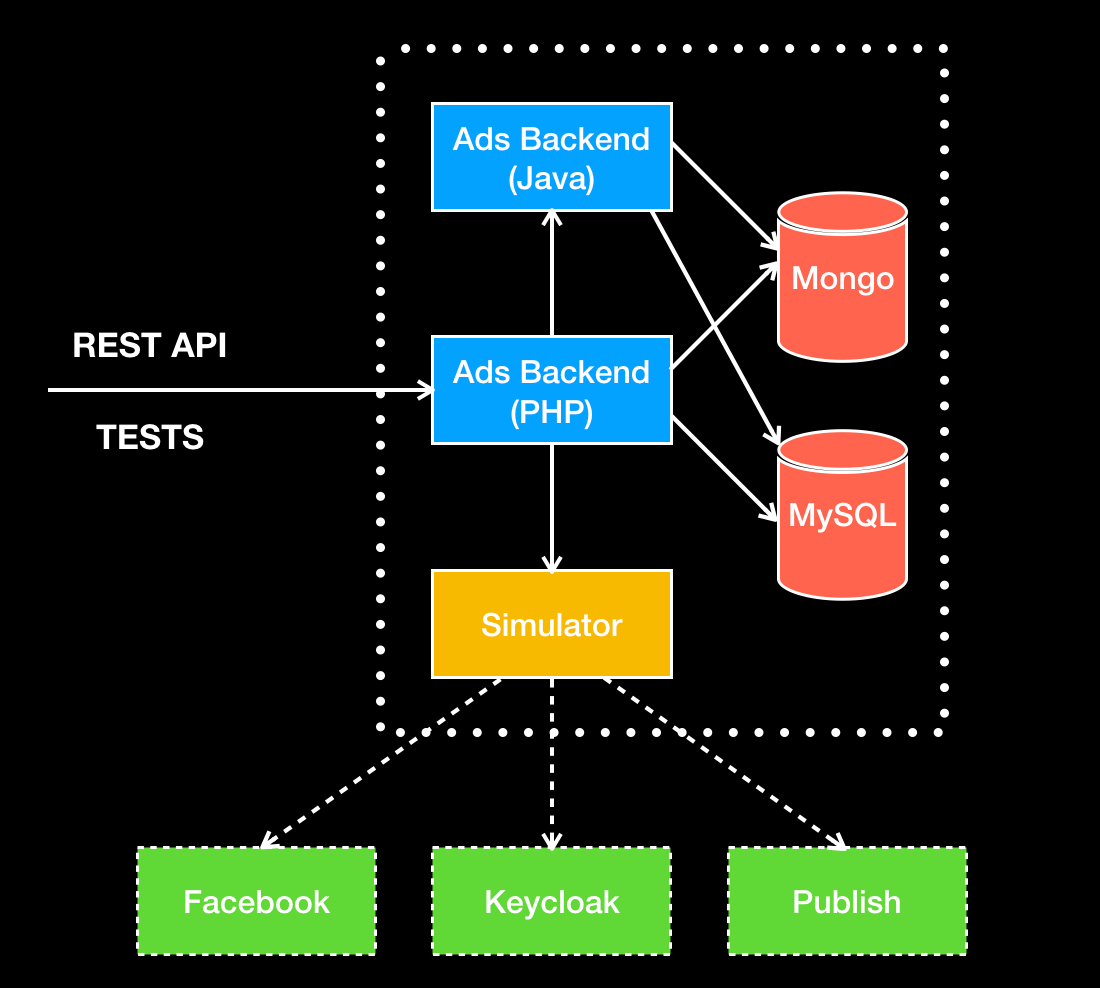
At my previous gig, we developed an HTTP simulator to help us to stub social networks (think of it like creating a mini-Facebook that we have full control over). In order to create such a setup, we need to append a line in each of the app’s containers /etc/hosts file to intercept and influence the traffic of the 3rd party services. Think of this as a man in the middle attack.
echo $SIMULATOR_IP api.instagram.com >> /etc/hosts
Deep Oracles
One of the great advantages of having a fully independent and dedicated test environment is that you can use it to find unknown and unexpected defects. As automated test detect only defects that they were programmed to detect, with dedicated test environment you can continue probing and looking for clues of defects. There are three main areas to look defects in:
- Logs. Look for any unexpected error or exception in the application or services logs
- Data. Look for bad, incorrect data, out of the ordinary.
- Metrics. Collect application metrics from the OS, database, filesystem, while the tests are running and then compare them to a baseline or threshold limits.
All of these techniques and more are described in a blog post also in this presentation. If you want to discuss these ideas in-person, I’ll be giving this talk at Agile Testing Days US, in Chicago, June 2019.
Here are some miscellaneous tips that did not fit any of the categories above:
- If parts of your app run interpreted code (PHP, Ruby, etc.), you can save some time and download/clone only the latest revision, because you don’t need the history. If you’re using Git:
git clone —depth=1 - If you use configuration services such as Zookeeper or ETCD, consider if you can substitute them (for automation test purposes) with plain text based config files. This can be done with an environment variable switch in the code. The result will be significant time savings as loading such configuration every time (i.e. to Zookeeper) leads to very slow setup time.
- If you use some sort of dedicated service for API authentication (like Keycloak), in order for your test to be hermetic, you either need to create such a dedicated service/container in your test environment, or to simulate it like any 3rd party dependency outside of your control (we’ve successfully simulated the Keycloak authentication mechanism with Nagual). There is a third way however, to use env variable to turn on and off the API authentication. It will not affect the functional tests in any way but you need to be careful not to mess up the deployments in production and leave the APIs unauthenticated.
- If your app uses message queues, consider that for testing purposed you can bypass them and execute synchronously the request. As this requires changes to the backend code, it is more intrusive to the functional tests than the bypass of the API authentication mentioned above. However, you’ll configure one less container and will speed test execution. Like all the tips in this section this is highly context specific.
- If you have company created base images for containers, by all means — use them. The same is true if you already have codified the way that your infrastructure is created. Utilize the infrastructure as code if you have such, don’t reinvent the wheel.
- In order to avoid setting up development environments make sure that you also containerize the environment in which you run your automated tests. Our tests used to be written in Ruby and we’d have to install RVM on the machined that runs the tests to manage the dependencies. Nowadays it’s easier to spin up a dedicated Ruby container and leave the host OS untouched (besides having Docker installed).