The Ultimate Feedback Loop

How We Decreased Customer Reported Defects by 80%
In April 2017 I was at CraftConf 2017 presenting The Ultimate Feedback Loop. InfoQ noticed this presentation and wanted to do a short interview about our results. When I sent the replies, they decided that it’s a valuable enough information and asked me to write a full article which can be found here.
I'm putting the article on this site to collect all my writings in one place.
Key Takeaways
- Analyzing the most expensive types of bugs will save companies time, money and resources
- The collected data will question widely believe dogmas in software development
- In service oriented architecture (or microservices), integration tests will uncover more defects than unit tests
- The majority of defects are concentrated in small number of easily identifiable functions
- Simple actions can greatly reduce the defects that reach the end customers
Introduction
Software defects found by customers are the most expensive ones. Lots of people are involved in debugging (hard to do in production), fixing and testing them. All those people also need to get paid, time and resources need to be allocated away from new feature development. Customer reported defects are also an embarrassment for an organization — after all they have bypassed all the internal defenses. It’s no wonder that software maintenance costs are typically between 40% and 80% of the project cost (according to some studies they may reach up to 90%: How to save on software maintenance costs), and a big chunk of those expenses is directly related to fixing defects. It’s easy to calculate the exact cost for a bug fix, but one thing that is hard to measure is the reputation loss. Customers will not recommend an app, or will downright trash it because of bad quality.
Our Situation
Most companies are not investigating the root cause of any defect (even the most expensive ones). And at Komfo we were no different. We accepted defects as the cost of doing business — never questioning or trying to improve. Since we couldn’t find any industry data related to customer reported defects to benchmarks with, initially, we just wanted to see where we stand.
Here is an example: Our customers can report a defect through a number of channels: email, phone call, social media. Of all the reports we get, only 12% end up with actual bug fixes in the code base. The other 88% are also interesting but for other reasons: maybe our product is not intuitive to use or maybe our customers need more training. 12% of bug fixes — is this good or bad? Until other companies start publishing such data there is no way to know.

A while ago, I read a book called “The Toyota Way to Lean Leadership”. In it, there is a story about how Toyota North America lowered the warranty costs with 60% by investigating the causes and the fixes of vehicle breakages within the warranty period. Inspired to so something similar, we started gathering data to investigate how we can improve.
Data Collection
All of our defects are logged in Jira. The defects are also tagged depending on in which phase they are found — in-house or reported by a customer. We gathered all the defects in the second group, ignoring those that were marked as will not fix, or were considered improvements. We were interested purely in the defects. We started searching in the git log for their Jira ID (we already had a policy to put the Jira ID in the commit message).
In the end, we found 189 defects and their fixes in the code base, spanning a period of two and a half years. For each defect we gathered more than 40 statistics: when it was reported and fixed, in which part of the application, by what kind of test or technique we could have detected it earlier, what was the size and the complexity in the method/function where the defect was located and so on (you can check the sanitized version of the stats we collected and use them as a guideline here).
The data collection process was slow as we were gathering everything by hand. We already had our daily work to do and investigating 189 defects, gathering 40+ stats for each of them took us more than 6 months. Now that we know what exactly we’re looking for, we’re automating the tedious data collection.
Initial Analysis
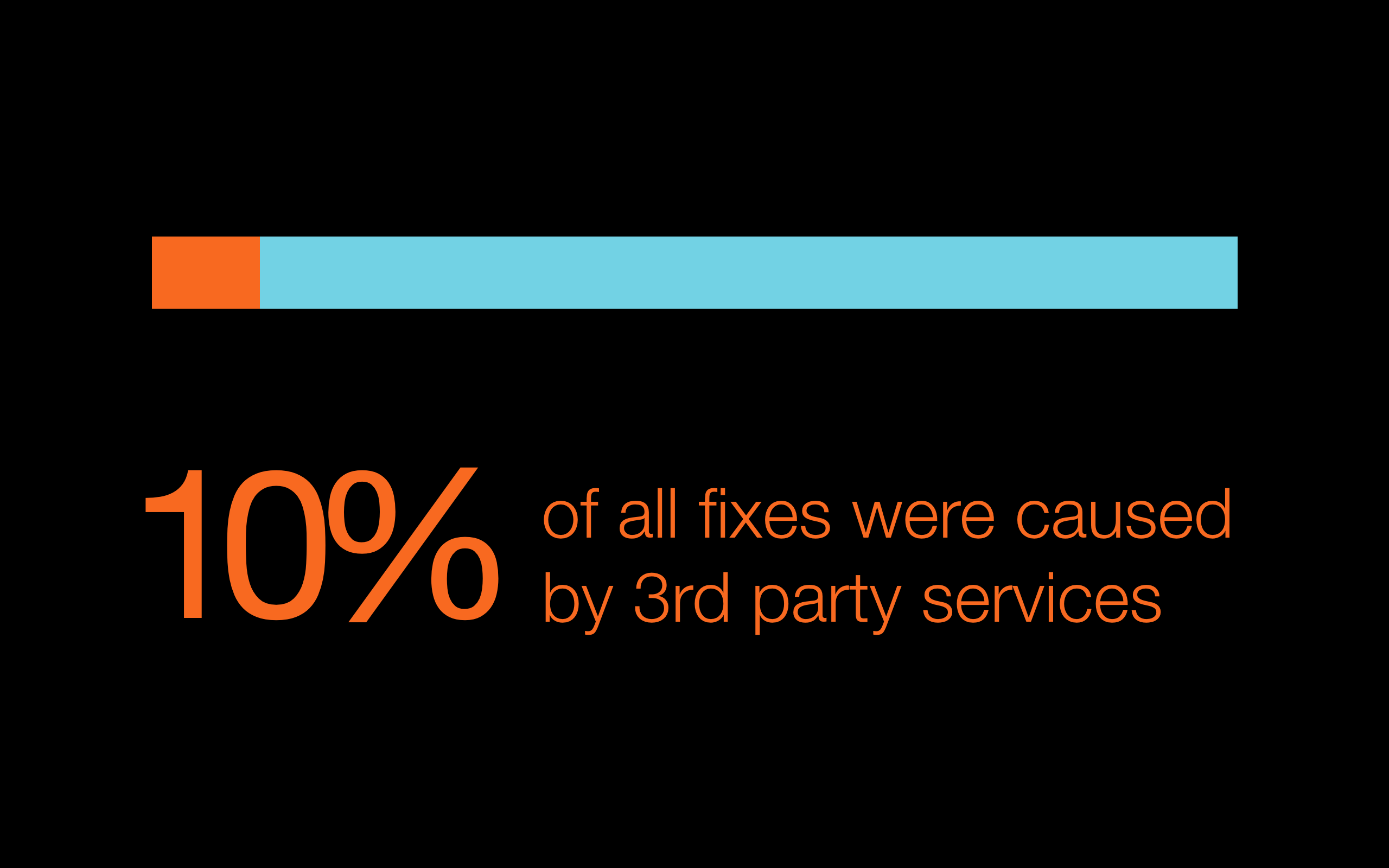
One of the first things we noticed was that 10% of all the defects we were interested in, were actually not caused by our developers. Our product is SaaS that collects lots of data from the biggest social networks (we make more than 10 million requests a day to Facebook API alone). Sometimes, the social networks change their APIs with no prior notification, then our customers notice a defect. All we can do is react and patch our product. We ignore those defects from further analysis as there is no way to notice them early.
Fronted to backend defect ratio was almost 50/50 - we have to pay close attention to both. The backend distribution was interesting though. Almost 2/3 of those defects were in the PHP code, 1/3 in the Java code. We had PHP backend from the beginning, and since a year a half ago we started rewriting parts of the backend to Java. So PHP was around for a long time accumulating most of the defects in the two and a half year period we investigated defect.
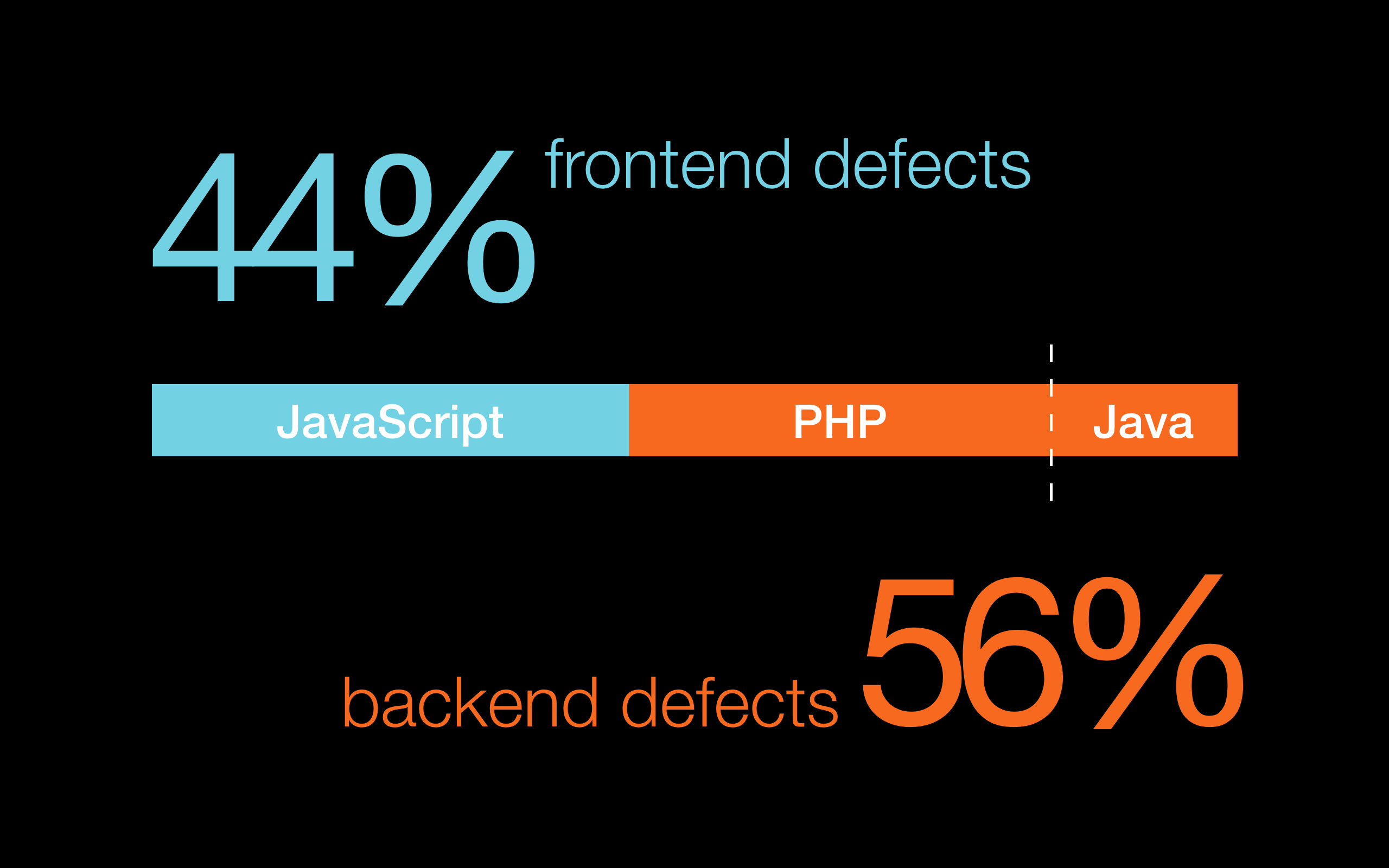
There are lots of discussions about which programming language causes less defects. We decided to find out empirically for our application - PHP or Java. Only 6% of the defects could have been avoided if the code they were found in was Java in the first place instead of PHP. In the PHP codebase we have lots of places where we don't know the type of a variable. There are extra variable checks in case it is a string, a date, a number or an object. In the Java codebase we know the variable type and no extra checks are needed (which are potential source of defects).
However, the 6% "Java advantage" is reduced by the fact that when rewriting parts of the backend from PHP to Java, we simply forgot to include some functionality and this resulted in defects. Also (and we have only anecdotic evidence about this), the developers feel that they are ‘slower’ developing in Java compared to PHP.
We started investigating customer reported defects since two and a half years ago. Back then, our backend (no pun intended) was written 100% in PHP. One year after that we started rewriting parts of it in Java. The new backend went live after 6 more months. We did not immediately see a decrease of incoming defects (see the last screenshot). Switching from PHP to Java did not automatically mean less defects. We started implementing various other improvements described below and we had to wait for 6 more months until the defects started to decrease. The rewrite was done with the same developers (we have very little turnover).
What all this means, according to our data, is that in the long run, the quality of a product depends primarily on the developers involved and the process used. Quality depends to a lesser degree on the programming language or frameworks used.
The Surprises
There were three main things that we did not expect and were quite surprising to us.

The first one was that 38% of all the customer reported defects were actually regressions. This means that there was a feature that was working fine, then we made a change in the codebase (for a fix or a new functionality) and then the customers reported that the feature they were using stopped working. We did not detect this in-house. We knew that we had regressions but not that their number was that high. This means that we didn’t had any sort of automated tests that would act as a detection mechanism to tell us: “that cool new code you just added is working, but it broke an old feature, make sure you go back and fix it before release”. By writing automated tests you kind of cement the feature logic in two places. This is double edge sword though. It is effective in catching regressions but may be hinder your ability move fast. Too much failing tests after commit slows you down because you have to fix them to before continuing. It’s a fine balancing act, but for us the pendulum had swung too far to the part where we preferred fast development, so we had to reverse the direction.
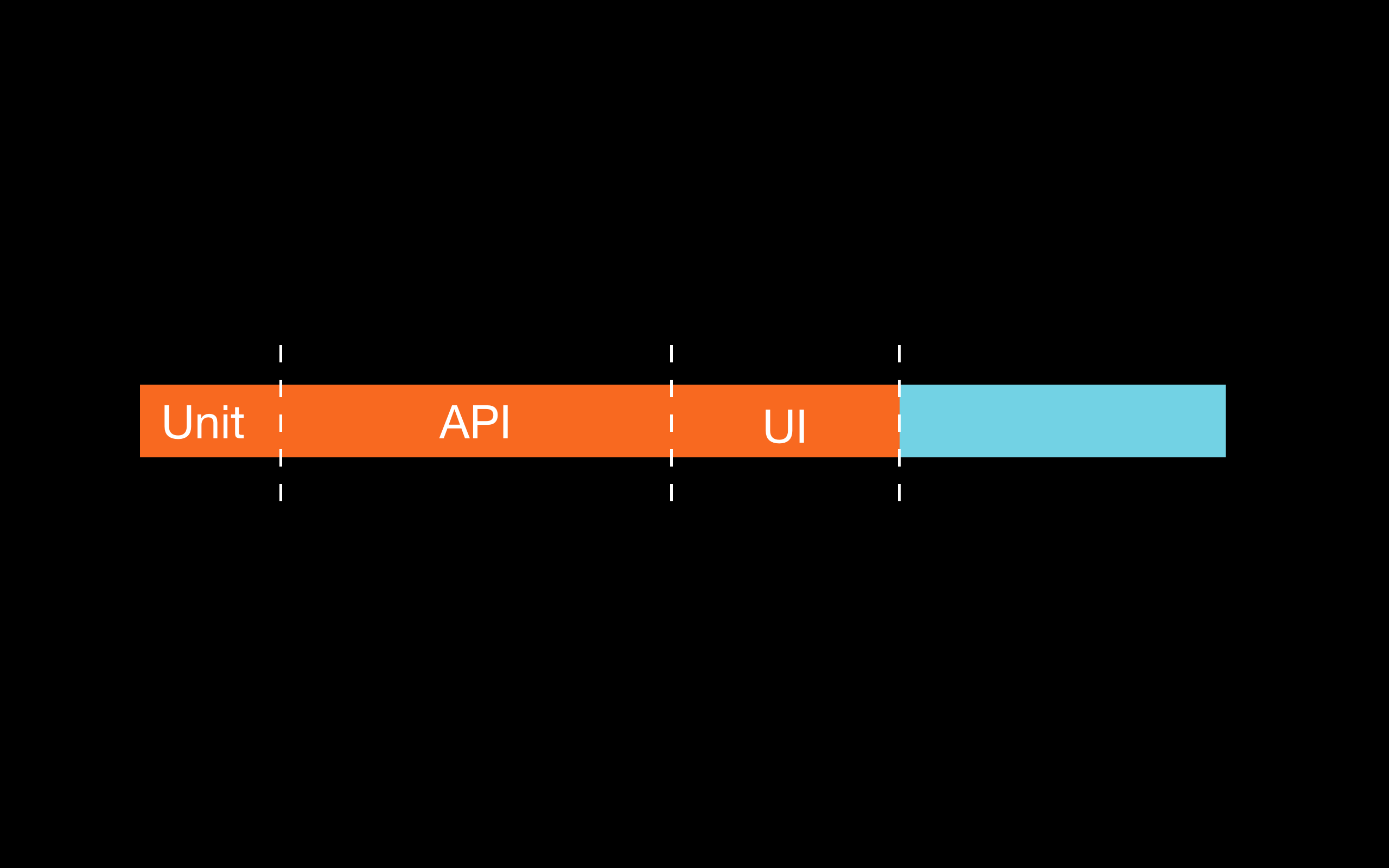
The second surprise was the fact that the automation testing pyramid guidelines were not helping us to catch more defects early. Only 13% of the customer reported defects could have been detected early if unit tests were written. Compare this to the 36% ‘yield’ of the API level tests and 21% ‘yield’ of the UI level tests. A diamond shape (the majority of the tests are API level) is better for us than a pyramid. This is due to the nature of our software. It’s SaaS and the bulk of what we do is gathering lots of data from the internet, then put it in different databases for later analysis. Most of the defects lay somewhere in the seams of the software. We have more than 19 different services, all talking over the network constantly. The code for those services is in different repositories. It is impossible to test efficiently with unit test only (we consider unit tests to run only in memory, don’t touch the network, the database of the filesystem; using test doubles if they have to). And we think that with the rise of the microservices and lambda functions, high level integration tests executed on fully deployed apps will be way more effective in detecting defects than simple unit tests. The majority of the defects lay somewhere in the boundaries between the services. The only way to detect them is to exercise a fully deployed application. Those defects can not be detected by testing a piece of code in isolation (with unit tests).

Unit tests are still useful but they don’t need to cover 100% of the code base. We found out that it was sufficient to cover methods with cyclomatic complexity 3 and above (72% of the defects were in such methods) and methods with size of 10 or more lines of code (82% of the defects were in such methods).

The third surprise was that no matter what kind of testing we do in-house, we cannot detect 100% of the defects. There will always be 30% defects that only our customers could find. Why is that? Edge cases, configuration issues on production, unintended usage, incomplete or just plain wrong specifications. Given enough time, money and resources, we can detect those 30%, but for us it does not make economic sense. We operate in a highly competitive market and we need to move fast. Instead of waiting forever to find those mythical 30%, we expect them to happen, and we try to optimize for early detection and fast recovery. When such defect is reported and fully investigated, we learn from it and improve our system further.
Actions
We made four process changes for developers and testers:
-
Write at least one automated test per feature. If possible, focus on API tests because they help us detect most of the defects.
-
Even for the smallest fixes, do manual sanity check and visual verification.
-
Mandatory code reviews performed by the team leads. No one can push code to production without an OK review.
-
When testing, use boundary values where possible: too much data, too little data, the end and the beginning of the year and so on, because 8% of the defects were caused by such values.
There were also four technology changes:
- Every morning we review the logs from production for the past 24 hours looking for errors and exceptions. If we notice something unusual we fix it with high priority. This way we end up noticing problems very early, and sometimes, by the time a customer calls us to report a problem, we are already working on the fix.

-
We had long running API integration tests that used to run for 3 hours. After some improvements (the major ones being: dedicated test environment, test data generation, simulation external services, running in parallel), the same tests now run for 3 minutes. We were invited to present how we did this at Google Test Automation Conference in 2016: Need for Speed - Accelerate Automation Tests From 3 Hours to 3 Minutes. This helps us tremendously in detecting defects because we run all the automated checks (static code analysis, unit tests, API tests) after each commit. We don’t have nightly test execution or smoke tests anymore. If all the checks pass, we can confidently and immediately release to production.
-
Defects in production sometimes cause exceptions that can be found in the log files of the application. Upon investigation we found that he same exceptions were present in the log files of our testing environments even before the release to production. It turns out that we had the opportunity to detect some defects before they reach production, if we monitor the logs in the testing environments. Since then, we made the following change in the automated test execution. Even if all the automated API tests pass successfully, we still check the log files for errors and exceptions after each test suite execution. A test may pass but still cause an internal exception which will not manifest itself (by failing test) because of bad coding practices (e.g. silently logging an exception and not propagating it further). In such cases, we fail the build and investigate the exception.
-
Around 10% of the defects were caused by unexpected data that we did not handle properly: special or unicode characters, binary data, malformed images. We started collecting this data and whenever our automated tests need to create test data they use this pool of ‘weird’ data.
The Outcome
In screenshot below, you can see the result of all the actions that we took. One bar corresponds to one quarter. Notice in the last four quarters, the customer reported defects are constantly decreasing. The last quarter we had less defects that any other quarter since we started collecting the statistics two and a half years ago. The difference between the last quarter and the one with the most defects is more than 4 times.
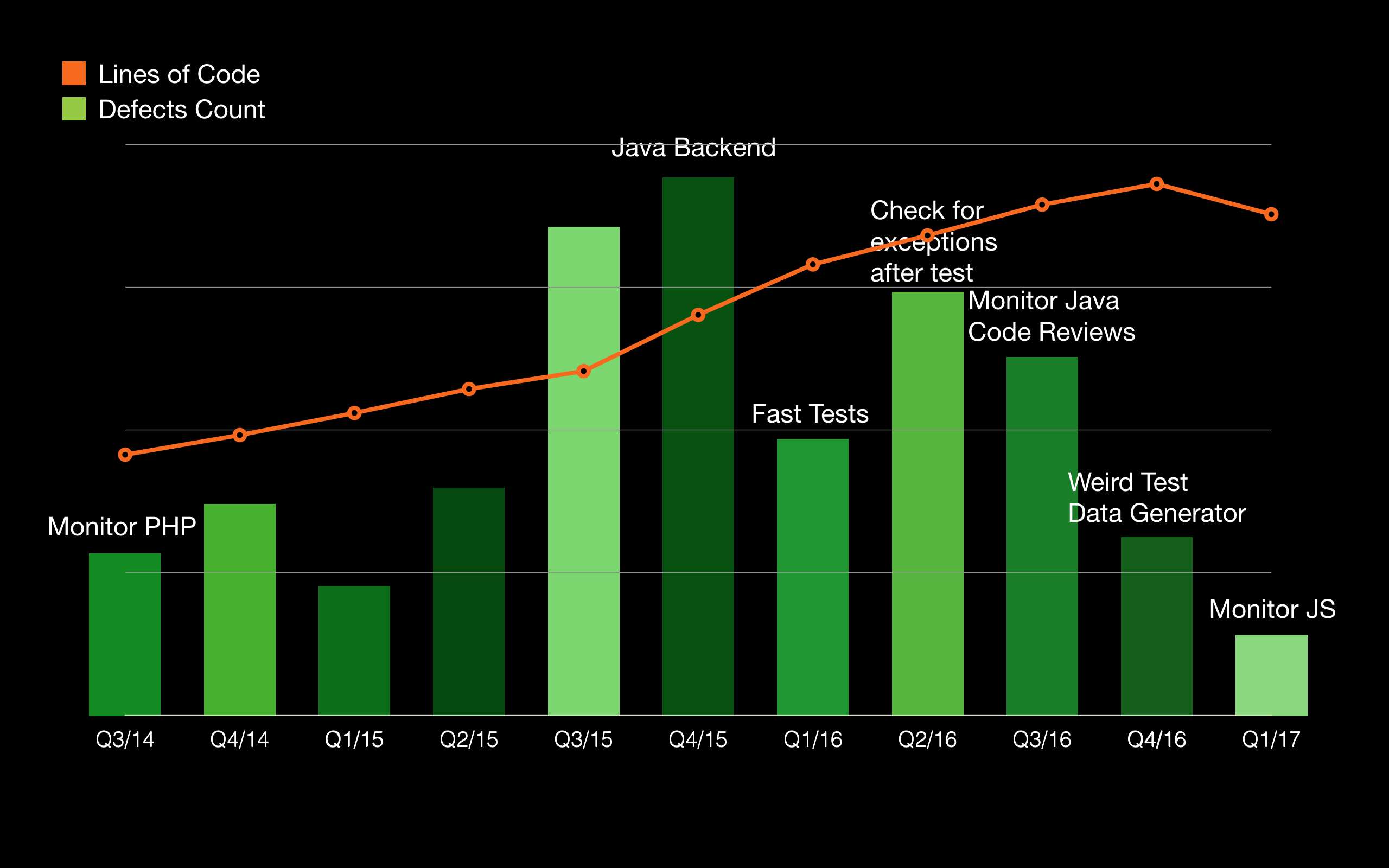
One last thing to note. Usually, the more lines of code (LoC) in a product, the more defects it contains. Defects count to LoC ratio remains constant. In our case, even though we kept adding more code, the defects count continued to go down in the last four quarters.
How to Start
-
The process of reviewing customer reported defects, finding the root cause, correlating it with the fix and gathering additional information is very tedious for most people. My advice would be to set aside a dedicated time(e.g. an hour a day) for defect investigation. Once you go over the initial hump, assuming you want to investigate defects found since a certain date in the past, you’ll get better and automate some of the data collection. Even with that however, I still don’t have the mental capacity to investigate defects eight hours a day.
-
Make sure that you have a way to separate the customers reported defects from the ones found in-house. When a fix is made, put the ID of the defect in the commit message so that you can correlate both later.
-
Investigate defects as soon as you can — the longer you wait, the more time it takes, as human memory fades quickly.
-
Have someone outside of the team investigating the defects. It should be done by a person that does not have an emotional connection with the code. Otherwise it’s very likely that his/her judgment will not be objective.
-
You can quickly get overwhelmed tracking too many metrics, figure which ones will be useful and actionable for you organization.
Collecting all this information may seem (and it is) a lot of work, but I promise you, it is worth every second you put into it. The learning opportunities are tremendous.
Conclusion
Investigating the root causes of customer reported defect will have great impact on your organization. The data collection is not easy when you start, but the learning opportunities are tremendous. It is amazing how many companies are not doing it. In times when most organization are competing for the same people on the job market, or have access to the same hardware resources (AWS) how do you differentiate? The best ways to ensure customer satisfaction, lower costs and increase employee engagement is to look inside — you already have the data. At the end, it’s all about continuous improvement.
Here are four book recommendations that will help you with your journey:
“The High Velocity Edge” by Steven Spear
“Antifragile” by Nassim Taleb
“Toyota Kata” by Mike Rother
“Moneyball” by Michael Lewis